架构
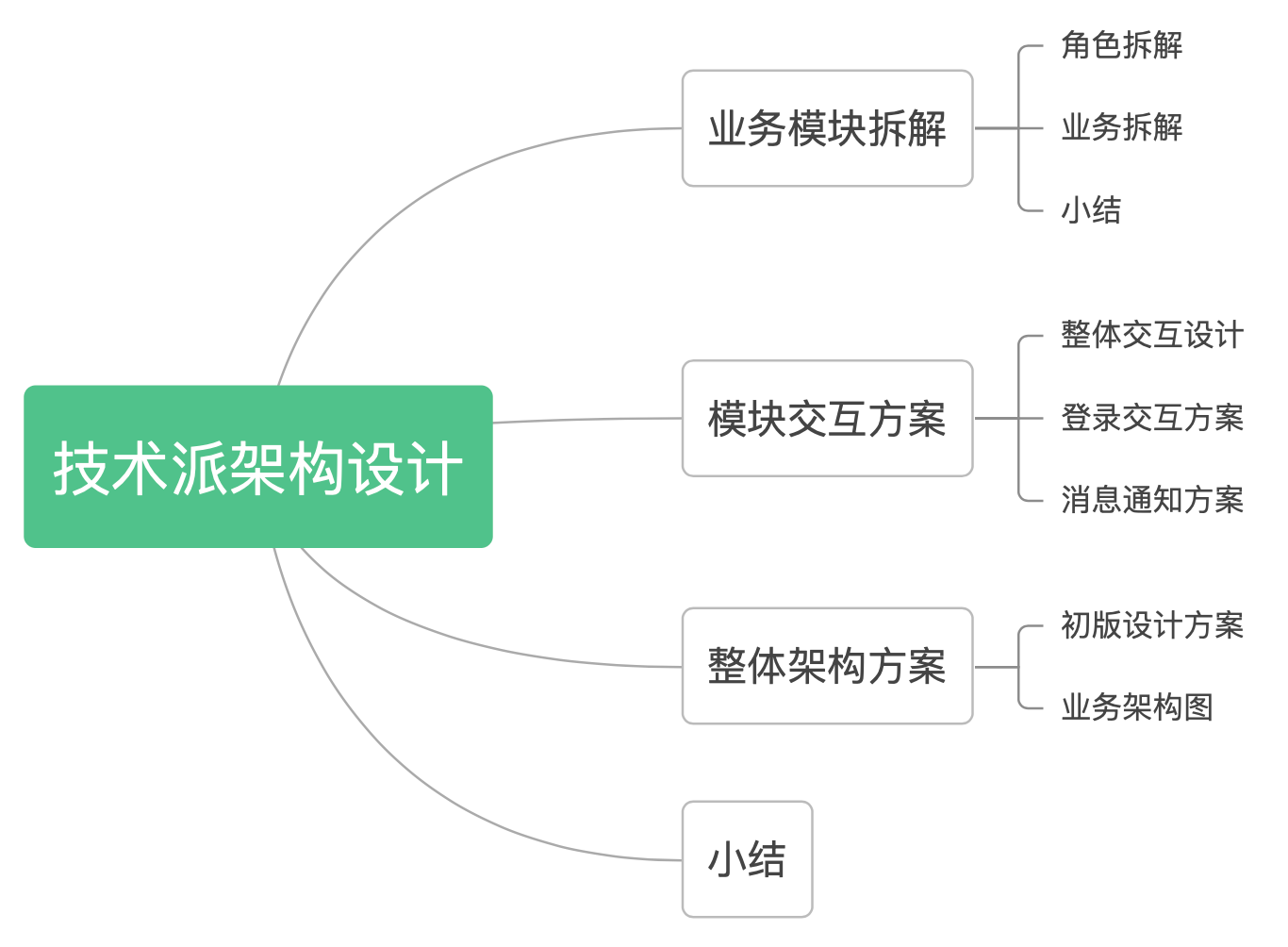
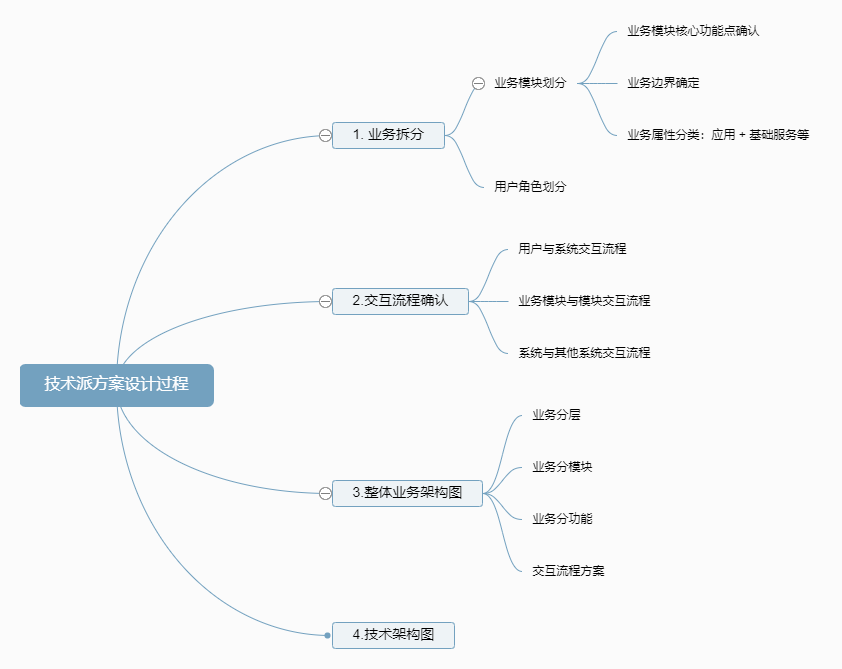
1.业务模块拆解
在查看本文之前,请确保已正确了解技术派的主营业务,覆盖的功能点,如有疑问,可以先体验一下技术派网站,访问地址:**https://paicoding.com**
在业务模块拆解这一过程中,除了业务属性维度之外,还有一个非常重要的属性是参与者角色。
1.1 角色拆解
作为一个社区系统,用户角色非常容易划分
- 读者:普通浏览文章的用户
- 作者:发布文章的用户
- 管理员:整个系统的超管
权限划分
那么这三个角色的权柄是怎么划分的呢?
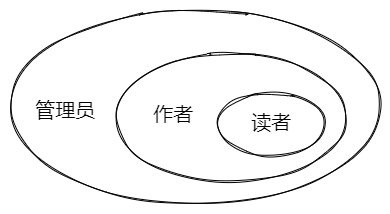
从上图可以比较清晰的看出三个角色的划分
- 读者的所有功能,作者都拥有;但是作者存在部分读者用不了的功能(如文章编辑、修改、发布等)
- 管理员权限最大,覆盖读者、作者的所有功能点
差异性划分
接下来就需要抓重点,看一下上面三个角色的主要差异点在哪里
- 读者:主要是阅读文章
- 作者:发布文章,作为信息输出
- 管理员:整个系统的运营管理,如标签、分类管理,文章审核等;通常不怎么参与文章的阅读发布
基于以上分析,我们可以将技术派的用户分为
- 普通用户:作为社区的注册用户,围绕文章主体展开其覆盖的业务功能点
- 管理员:作为官方角色,主要负责整个社区的生态运营
1.2 业务拆解
整个社区系统,按找业务边界先进行一版本初始划分:
- 用户
- 文章
- 评论
- 专栏
- 消息通知
然后再针对上面的进行简单的细化拆分
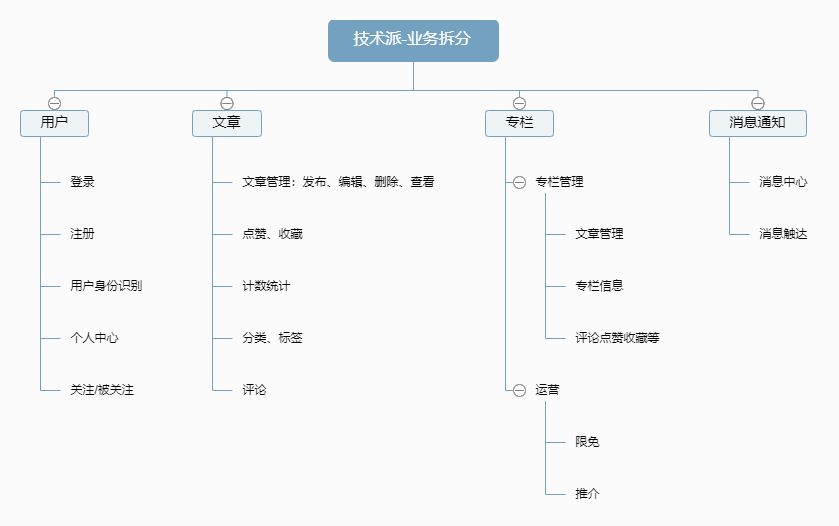
再上面进行简单拆分之后,会发现几个关键点
专栏:实际上是一些文章的合集,因此专栏的很多功能点可以直接建立在文章的基础上
评论:评论实际上也是依托于文章的点评,因此它于文章的关联性很强
消息通知:
- 消息通知的触发点需要进一步确认,但是它本身又属于一个相对独立的业务板块,因此重点关注交互方式
- 什么样的需要通知?如何触发通知?
- 怎么通知给用户?
点赞、收藏、计数统计
- 这种与业务相关,但是又可以抽离于业务之外独立存在,可以考虑建设通用的服务能力
独立于核心业务功能之外的能力:
社区的搜索、推荐,虽然不影响核心业务功能,但是否需要考虑?
社区运营
基于以上,我们进行业务模块拆分,先确定以下板块
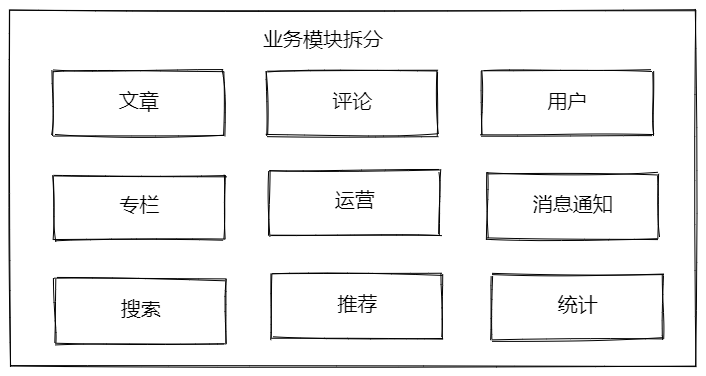
1.3 小结
通常,在业务拆解这里,希望达到的目的是让参与者,能知晓这个项目的整体情况,可以划分为多少业务域,明确业务模块的主营范畴,确定彼此的边界
在这一阶段,我们可以先对技术派的整体拆分,得出以下结论:
角色
- 普通用户:作为社区的注册用户,围绕文章主体展开其覆盖的业务功能点
- 管理员:作为官方角色,主要负责整个社区的生态运营
业务模块
业务侧:
- 文章
- 评论
- 专栏
- 用户
- 运营
基础功能测:
- 推荐
- 搜索
- 统计
- 消息通知
注意
- 一般来说,在整体设计阶段,每个业务模块,需明确的是主体业务功能,但并不需要拆解到一个一个具体的功能点,具体的功能点,放在详细设计中来体现
- 业务的拆解不是一蹴而就的,相反实际情况下,这个拆解经常会出现反复、变动的情况(如果有留心公司的组织结构调整的小伙伴,应该对这种情况不难理解)
2.模块交互方案
接下来我们就需要将上面拆分的角儿和业务模块串联起来,看一下我们的整个系统是怎么玩的
2.1 整体交互设计
对于技术派的核心玩法,在于作者发布文章,读者阅读文章;整体交互相对清晰简单,实际上这一块是可以省略的;当然我这里也补上这个流程,主要以文章发布,到读者阅读文章,并点赞,作者获取通知这个流程,来串一下这个系统的整体交互流程
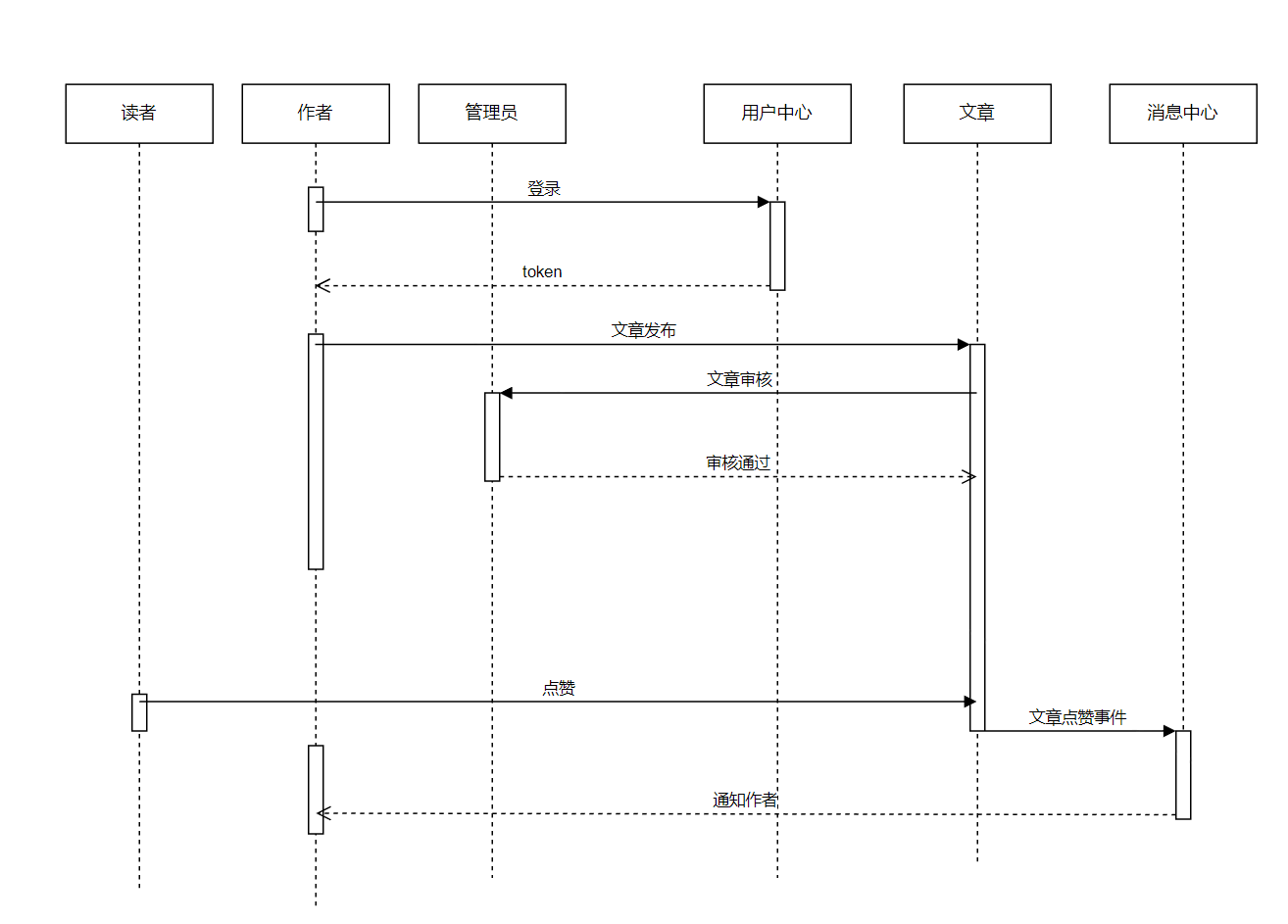
上面这个交互过程中,用户中心、文章、消息中心,可以是独立部署的服务,也可以是一个进程内的服务;但是从逻辑上,他们彼此是独立的;针对上面的操作流程,可以提炼下面几个点
用户首先通过用户中心登录系统
- 具体的登录方式可以是传统的用户名/密码,也可以是手机号验证码,亦或者是第三方OAuth2.0登录
- 登录之后,用户身份识别,可以是单机的cookie/session, 也可以是分布式会话,jwt等形式
文章发布
- 正向逻辑为作者发布文章
- 文章审核对于作者而言,则属于被动接收,即存在一个依赖关系,是自动审核,还是人工审核? 人工审核怎么通知管理员来审核?
消息通知
- 读者给文章点赞之后,如何将点赞通知给作者?
- 这个点赞事件是同步触发给作者,还是异步?
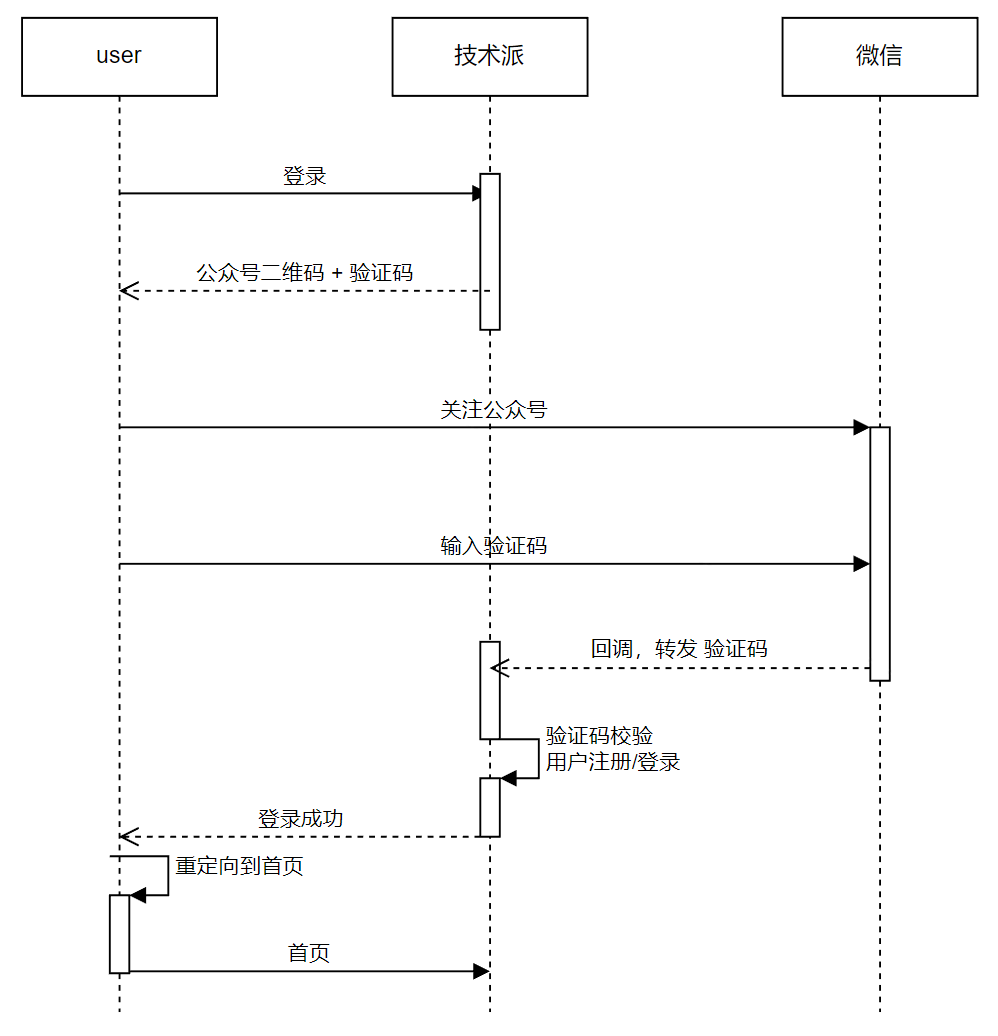
2.2 登录交互方案
登录交互我们最终选择的方案是基于微信公众号来实现的,下面这个交互方案适用于个人公众号(如果是企业公众号,可以直接使用微信的相关的API)
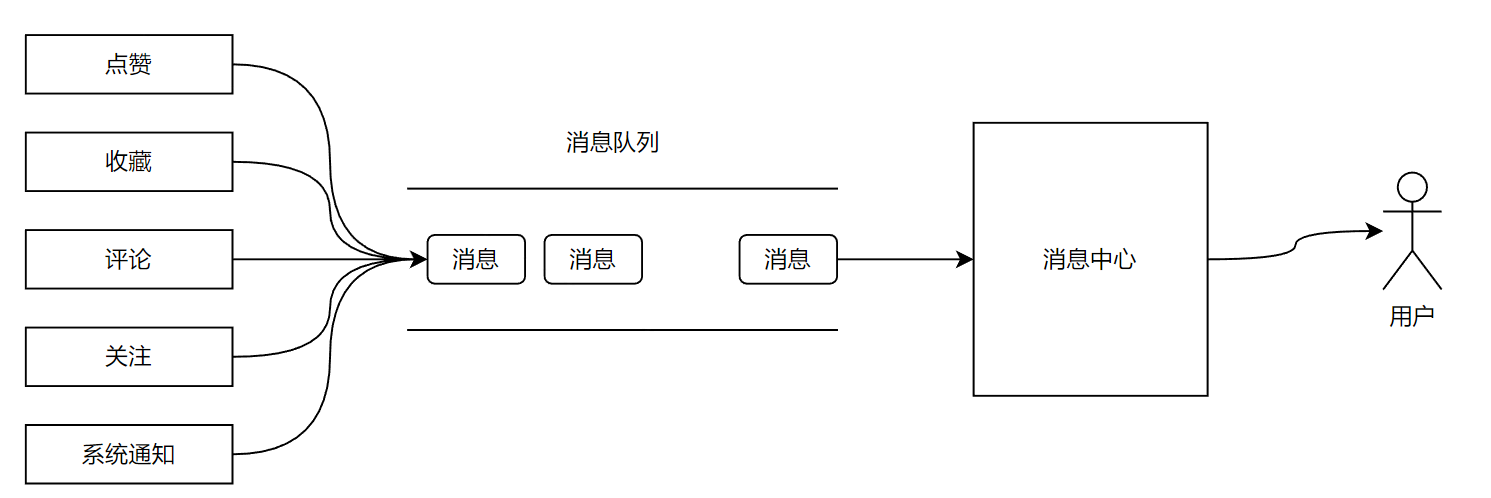
2.3 消息通知方案
消息通知采用异步驱动,通过Event/Listener方式来实现解耦
3.整体架构方案
上面的流程走完之后,接下来就是敲定整体的架构方案,通常一个好的架构方案一张图就完事了,注意越是前期在意的越不是细节
3.1 初版设计方案
下面这张图来自于技术派开始做之前绘制的,与最终的实现版稍有差异,无需在意细节🤭
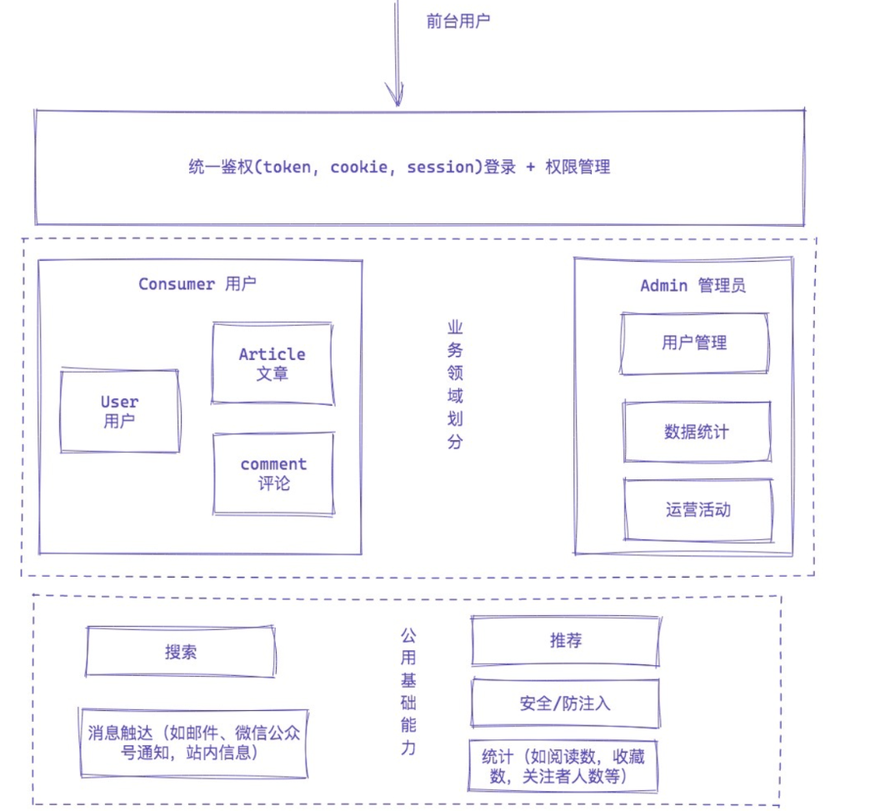
最初版的方案设计非常简陋,当然思路还是比较清晰的
从上面这个图,是否能抓住整个技术派的业务模块?是否能确定业务模块的定位(哪些偏业务属性,哪些偏技术属性)? 是否能确定不同角色的侧重点?
能满足上面三个点,和其他人进行沟通时,不会产生歧义即可;当然上面这个图是缺少交互方案的,通常在业务架构图中,不太会整这个,有放在细节里进行铺开,也有放在详细设计中的
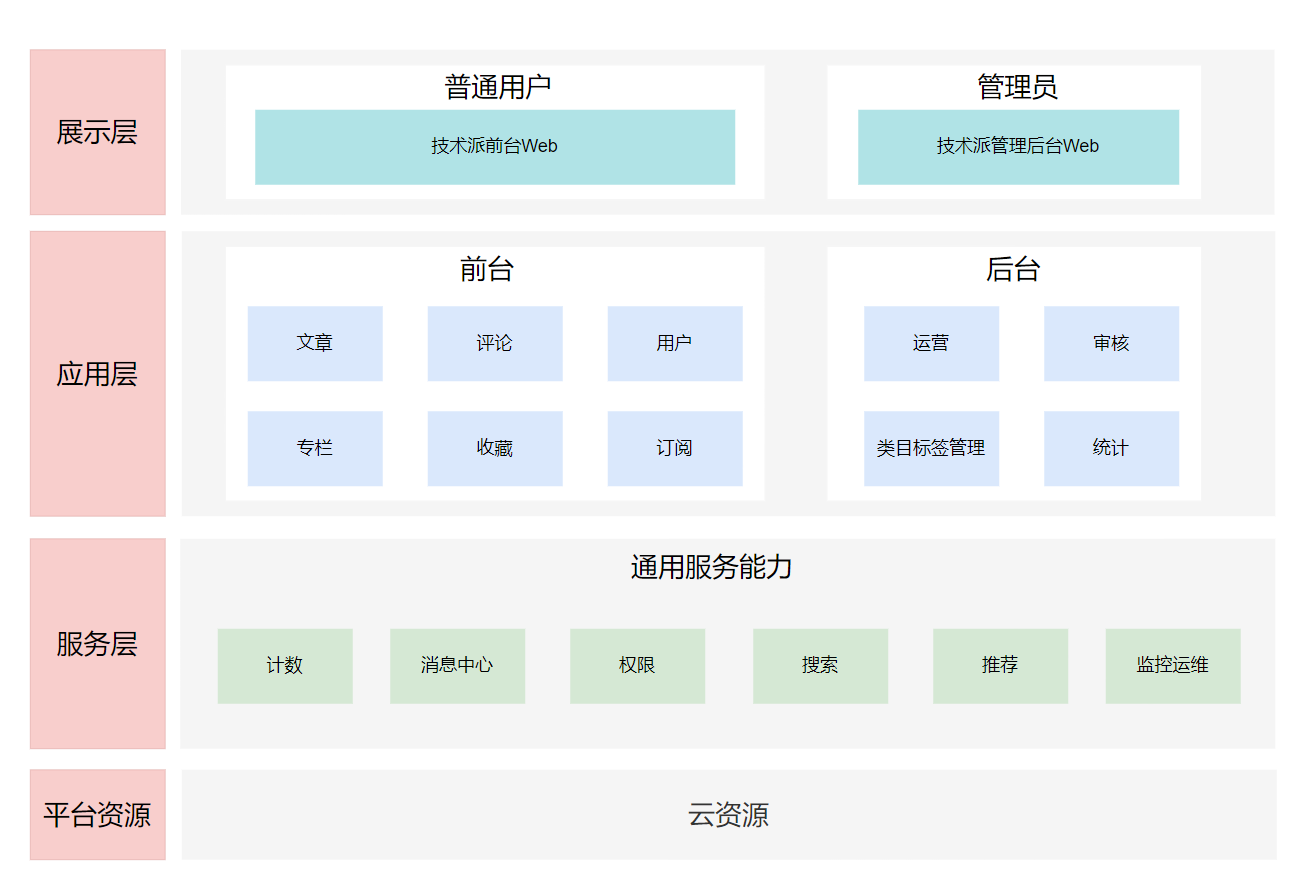
3.2 业务架构图
接下来看一下技术派最终定稿的整体业务架构图,如下:
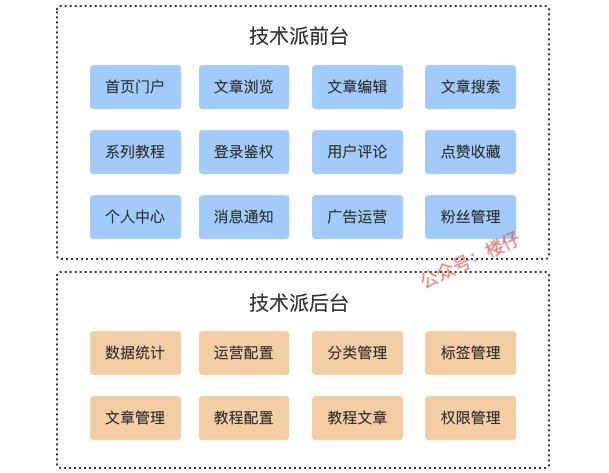
再看一下前后台的业务拆分
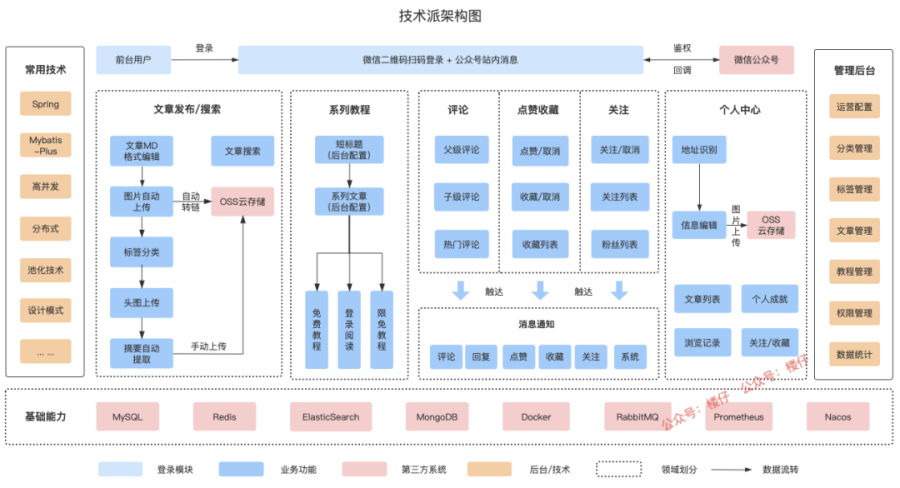
最后再看一下技术派的技术架构图
4.小结
这一篇不算是正规的技术架构方案说明书,更多的是将整个方案的落地过程给大家刨析了一遍,算是抛砖引玉,希望可以给大家今后写架构方案提供一点帮助。
现在总结的方案设计思路如下:
是不是还没看爽?
整个技术派教程一共 120 篇,每一篇都是高水准,对于需要学习技术派项目的同学,可以报名技术派星球,关于技术派更多的介绍,可以戳这里【技术派知识星球】。
我们团队有最厉害的技术大佬【一灰】,曾担任过技术总监,技术水平远在楼仔之上,基本没有搞不定的技术问题!
对于简历指导,已经指导过十几位同学,毕竟当了几年的大厂面试官,给的建议绝对实用!
星球还包含学习规划辅导,如果你比较焦虑、迷茫,找不到学习方向和重点,加入我们,一定能给到你最实用的帮助!
我们这个星球,有项目、有技术、有个人计划、甚至连简历指导都包括,对于这样的星球,券后仅 99 元,现在 QQ 音乐会员也要 89 元,我们这个真的是良心价!

注意!!先不要着急退出,你可以先扫码,进入到支付页面后,会看到星球内部的部分内容,就能基本知道这个星球的质量,然后再决定是否购买哈~~
开启新项目要考虑的事情
业务模块拆解
首先对业务模块进行拆解,除了业务属性纬度以外,还有一个很重要的属性就是参与者角色。
首先对功能、模块划分、概要设计,详细设计有初步的了解。
主要就是功能模块设计 + DB 的设计。
启动项目
mysql 启动
redis 启动:
路径 : D:\workTools\Redis-x64-3.2.100
redis-server.exe redis.windows.conf
启动成功,点击进入首页: http://127.0.0.1:8080
跑环境
D:\sys\Desktop\Workplace\IDEA_Projects\paicoding下载位置
git clone git@github.com:itwanger/paicoding.git D:\sys\Desktop\Workplace\IDEA_Projects\paicodinggit 下载
git clone 出现报错 , 原因:github ssh 秘钥没有配置 1
打开运行,输入services.msc,确定
找到 OpenSSH Authentication Agent 服务,需开启它.
ssh-keygen -t rsa -C “你的邮箱地址”
我用的是Administrator用户,执行完后,可以在 C:\Users\Administrator.ssh 目录下生成 id_rsa 和 id_rsa.pub 这两个文件。如果你没有用Administrator用户,也是在类似的目录下
项目结构
该项目主要有五个模块,各模块功能如下:
paicoding-api:
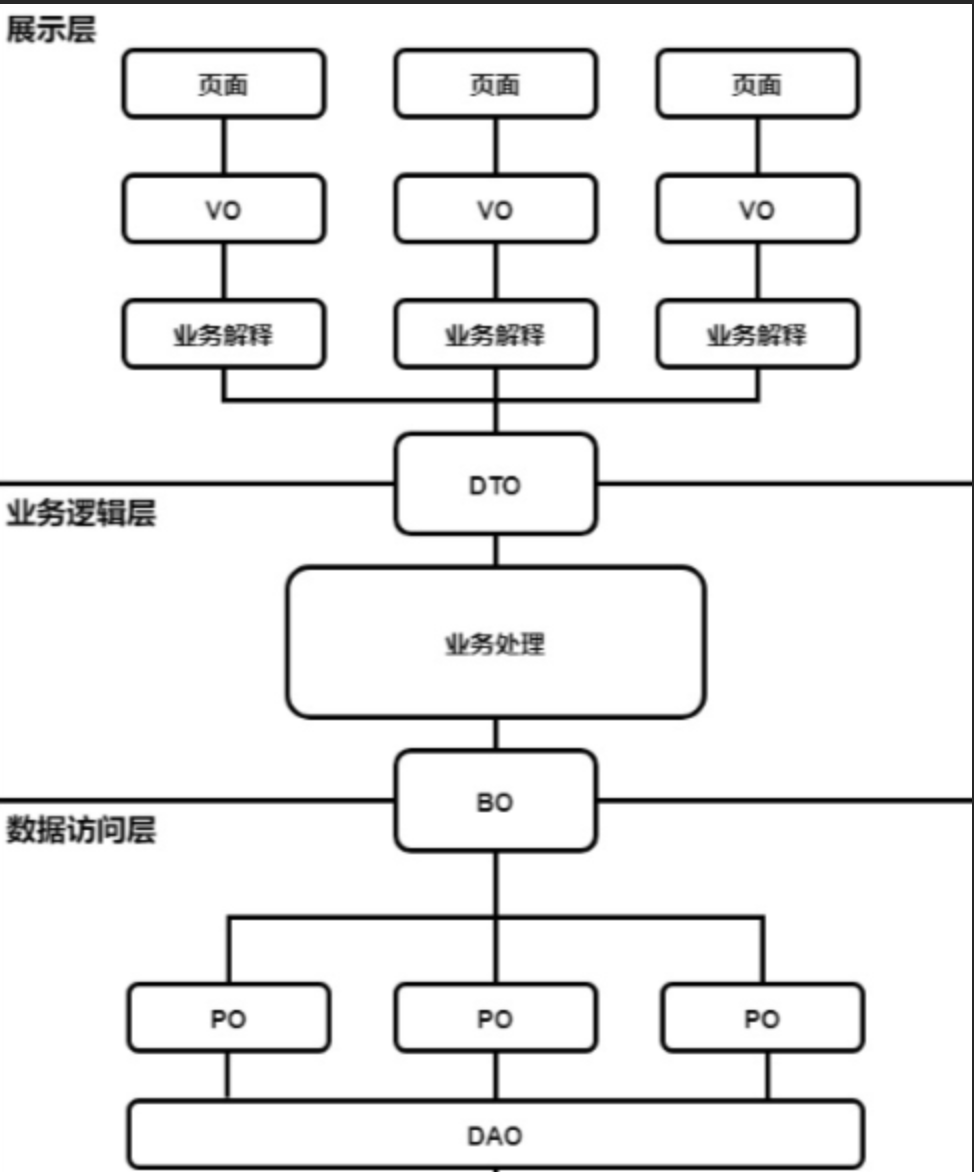
用于定义一些通用的枚举、实体类,包含 DO(数据对象)、DTO(数据传输对象)、VO(视图对象)等,为不同层之间的数据交互提供统一的格式和规范。
paicoding-core:
核心工具和组件相关的模块,像工具包 util 以及通用的组件都放在这里。按照包路径对模块功能进行拆分,例如搜索、缓存、推荐等功能组件。
paicoding-service:
服务模块,负责业务相关的主要逻辑,数据库(DB)的操作都在这个模块中进行。
paicoding-ui:
存放 HTML 前端资源,包括 JavaScript、CSS、Thymeleaf 等,主要用于构建用户界面。
paicoding-web:
Web 模块,是 HTTP 请求的入口,也是项目启动的入口,同时包含权限身份校验、全局异常处理等功能。
web 模块:
admin:
admin 目录存放和管理后台相关的代码,主要处理管理员对系统的管理操作。
common:
common 一般用来存放项目通用的代码,提高代码的复用性和可维护性。
comoinent:
TemplateEngineHelper
Thymeleaf模版渲染引擎,通过末班引擎进行服务端渲染(SSR),在初次渲染速度方面有显著优势。
config
ForumDataSourceInitializer
用来进行数据库表的初始化,首次启动时候执行:
DbChangeSetLoader
杂项笔记
请求参数解析
如果一个请求不会引起服务器上任何资源的状态变化,那就可以使用 GET 请求
AOP
技术派中的 AOP 记录接口访问日志是放在 paicoding-core 模块下的 mdc 包下。
三层架构
为什么要使用微服务而不是单体项目呢?
用不用微服务取决于业务量,能用单体的绝对不用微服务,毕竟单体的好处显而易见,当业务简单的时候,部署非常简单,技术架构也简单,不用考虑微服务间的调用什么的,但是随着业务的复杂,单体的缺点也就暴露出来了,例如修改一个模块上线,就要整个服务下线,这在某些业务中是不被允许的,其次单体复杂度高了,部署就缓慢了,出现问题排查也很困难,这些的前提就是业务复杂度提高了。
所以微服务的出现在我看来最初就是为了解决业务复杂单体所出现的问题的,将业务拆分到不同的模块,不同的模块单独部署开发,提高了开发效率,节省了维护时间成本,问题排查也方便了很多,微服务也并不是没有缺点,只不过是维护一个平衡,例如需要引入注册中心,为了方便配置的修改,还需要引入配置中心,不可能修改一个配置重新打包发布,服务间的调用组件,很多都是为了使用微服务而引入的。
所以没有哪种技术更好,只有哪种技术更符合当下的业务,抛开业务谈技术,在我看来并不是那么可靠。
工厂模式
创建型设计模式,定义一个创建对象的接口,但让实现这个接口的类决定实例化哪个类。
工厂方法把类的实例化延迟到子类中进行。
@Bean 就是一个工厂方法
各种注解
@Slf4j
@Slf4j:借助 Lombok 自动添加 SLF4J 日志记录器,简化日志记录代码。
@Value
@Configuration
@Configuration:把类标记为 Spring 配置类,允许在类里使用 @Bean 注解定义 Spring Bean。
在 Spring 应用启动时,Spring 会扫描带有 @Configuration 注解的类,将其作为配置类来处理,把类里使用 @Bean 注解定义的方法返回的对象注册到 Spring 容器中。
@Component
@Component:通用的组件注解,用于标记一个类为 Spring 组件,Spring 会自动扫描并将其注册到容器中。
@Service
@Service:@Component 的特殊化注解,通常用于标记服务层类。
@Repository
@Repository:@Component 的特殊化注解,通常用于标记数据访问层类。
@Controller
@Controller:@Component 的特殊化注解,通常用于标记 Web 控制器类。
@Bean
@Bean注册一个实体类
@
册一个实体类
实体对象
用 GET 还是 POST
GET - 从指定的资源请求数据。
POST - 向指定的资源提交要被处理的数据。
GET 请求是 HTTP 协议中的一种请求方法,通常用于请求访问指定的资源。如果一个请求不会导致服务器上任何资源的状态变化,那你就可以使用 GET 请求。
Filter过滤器
- 首先进入 filter,执行相关业务逻辑
- 若判定通行,则进入 Servlet 逻辑,Servlet 执行完毕之后,又返回 Filter,最后在返回给请求方
- 判定失败,直接返回,不需要将请求发给 Servlet
过滤器的使用
如果要使用过滤器,实现 Filter 接口,需要重写 doFilter 方法,在方法中编写过滤逻辑。
init: 初始化时执行
destory: 销毁时执行
doFilter: 重点关注这个,filter 规则命中的请求,都会走进来
三个参数,注意第三个 FilterChain,这里是经典的责任链设计模式
执行 filterChain.doFilter(servletRequest, servletResponse) 表示会继续将请求执行下去;若不执行这一句,表示这一次的 http 请求到此为止了,后面的走不下去了
过滤器在项目中的应用
- 身份识别,并保存身份到
ReqInfoContext上下文中 - 记录请求记录
- 添加跨域支持
跨域问题:
跨域问题(CORS)的本质是浏览器的安全限制,而代理服务器是解决该问题的关键方案之一。以下通过场景化解析帮你彻底理解代理机制.
假如说:
前端:运行在 http://localhost:5700
后端:运行在 http://localhost:8080
问题:前端直接请求后端接口时,浏览器会拦截并报错:
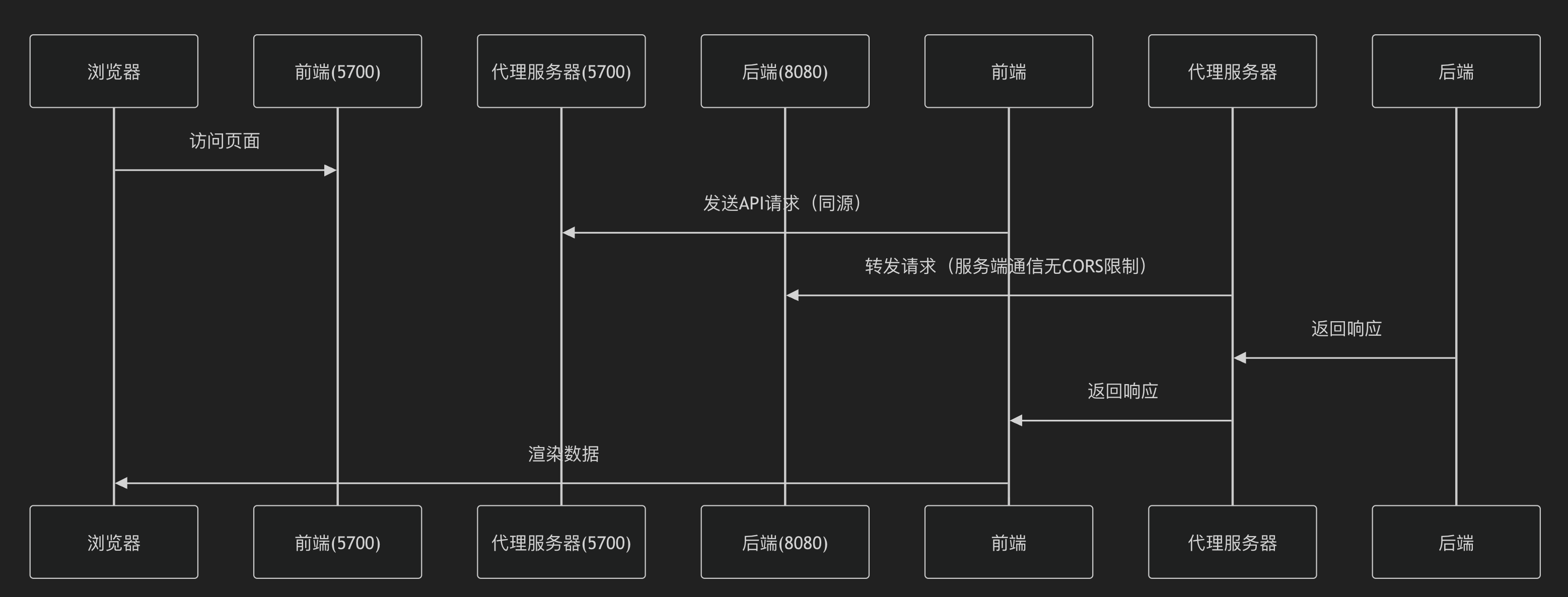
代理与服务器间的通信属于服务器之间的通信,不受浏览器同源规则的约束.
Servlet
Servlet的使用姿势,以及注册自定义的Servelt的四种姿势
● @WebServlet 注解:
在自定义的servlet上添加Servlet3+的注解@WebServlet,来声明这个类是一个Servlet
和Fitler的注册方式一样,使用这个注解,需要配合Spring Boot的@ServletComponentScan,否则单纯的添加上面的注解并不会生效
1 | /** |
还需要配置启动类
1 |
|
● ServletRegistrationBean bean定义
在Filter的注册中,我们知道有一种方式是定义一个Spring的BeanFilterRegistrationBean来包装我们的自定义Filter,从而让Spring容器来管理我们的过滤器;同样的在Servlet中,也有类似的包装bean: ServletRegistrationBean
自定义的bean如下,注意类上没有任何注解:
1 | public class RegisterBeanServlet extends HttpServlet { |
接下来我们需要定义一个ServletRegistrationBean,让它持有RegisterBeanServlet的实例
1 |
|
● ServletContext 动态添加
这种姿势,在实际的Servlet注册中,其实用得并不太多,主要思路是在ServletContext初始化后,借助javax.servlet.ServletContext#addServlet(java.lang.String, java.lang.Class<? extends javax.servlet.Servlet>)方法来主动添加一个Servlet
所以我们需要找一个合适的时机,获取ServletContext实例,并注册Servlet,在SpringBoot生态下,可以借助ServletContextInitializer
1 | public class ContextServlet extends HttpServlet { |