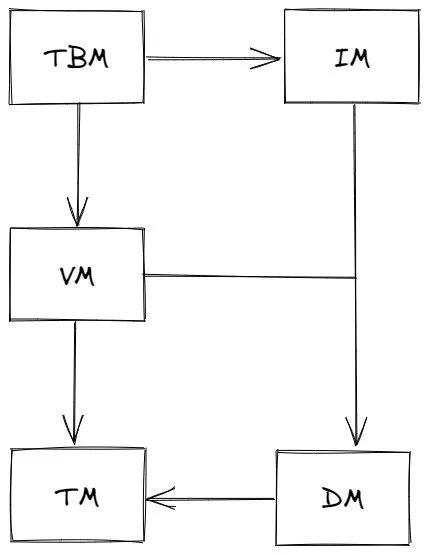
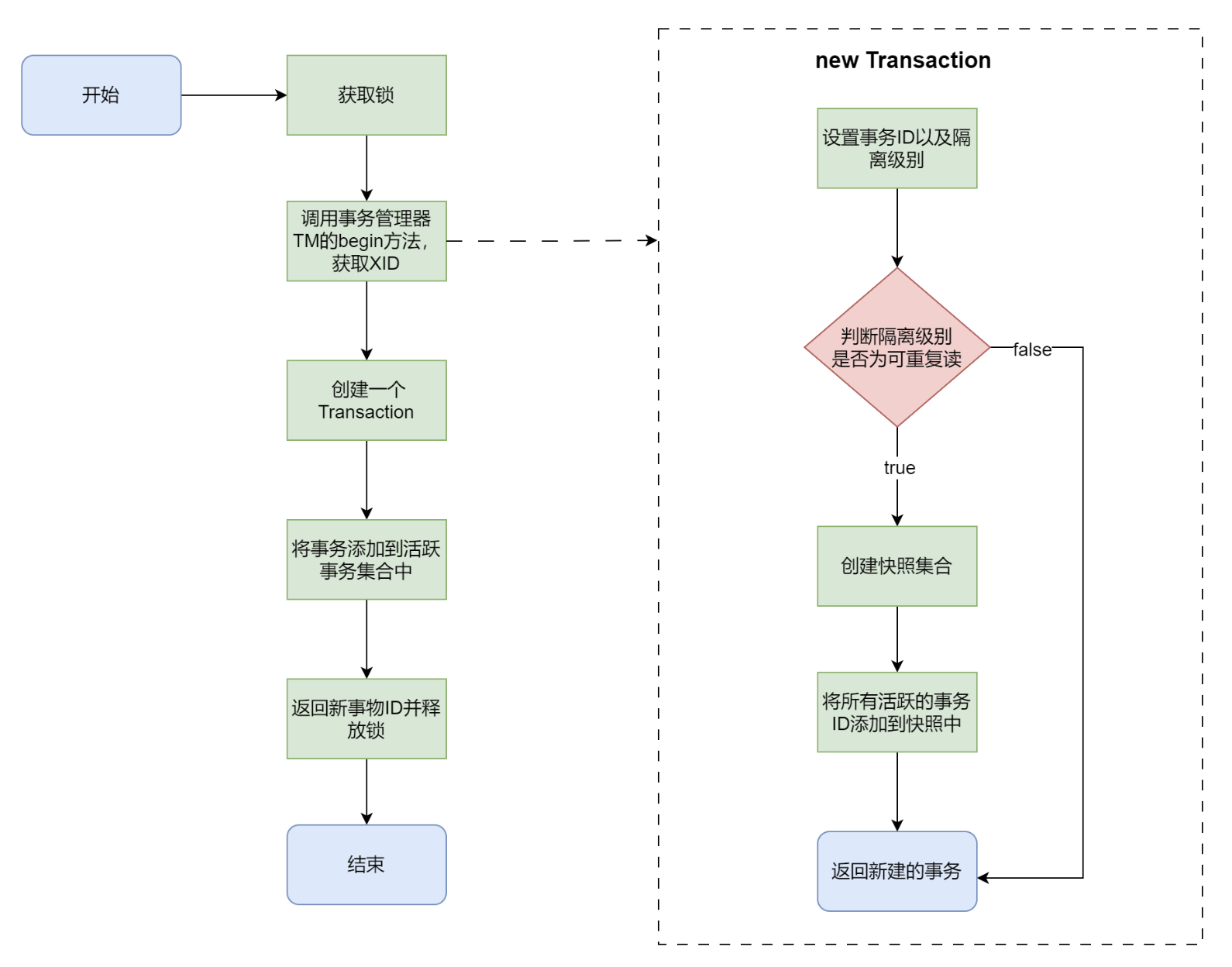
MYDB项目结构 整体结构
MYDB 分为后端和前端,前后端通过 socket 进行交互。
Transaction Manager (TM)
Data Manager (DM)
Version Manager (VM)
Index Manager (IM)
Table Manager (TBM)
这是五个模块的依赖关系图:
每个模块的职责如下:
TM 通过维护 XID 文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态。
DM 直接管理数据库 DB 文件和日志文件。DM 的主要职责有:1) 分页管理 DB 文件,并进行缓存;2) 管理日志文件,保证在发生错误时可以根据日志进行恢复;3) 抽象 DB 文件为 DataItem 供上层模块使用,并提供缓存。
VM 基于两段锁协议实现了调度序列的可串行化,并实现了 MVCC 以消除读写阻塞。同时实现了两种隔离级别。
IM 实现了基于 B+ 树的索引,BTW,目前 where 只支持已索引字段。
TBM 实现了对字段和表的管理。同时,解析 SQL 语句,并根据语句操作表。
TM(Transaction Manager) 事务管理器 总结 TM模块主要用于管理事务,包括开始、提交、回滚事务 ,以及检查事务的状态。在类中需要定义一些常量来管理事务如LEN_XID_HEADER_LENGTH、XID_FIELD_SIZE、FIELD_TRAN_ACTIVE、FIELD_TRAN_COMMITTED、FIELD_TRAN_ABORTED、SUPER_XID和XID_SUFFIX,分别表示XID文件头长度、每个事务的占用长度、事务的三种状态、超级事务、XID文件后缀。
还需定义一个RandomAccessFile 类型的file和一个FileChannel类型的fc,用于操作XID文件。还有一个xidCounter用于记录事务的数量,以及一个Lock类用于保证线程安全。然后会在构造函数中给file和fc赋值,然后调用checkXIDCounter方法检查XID文件是否合法。
begin方法用于开始一个新的事务,commit方法用于提交事务,abort方法用于回滚事务。这三个方法内部都会调用updateXID方法,将事务ID和事务状态写入到XID文件中。begin还会调用另外一个incrXIDCounter方法,用于将XID +1并更新XID Header。
isActive、isCommitted和isAborted方法用于检查事务是否处于活动、已提交或已回滚状态。这三个方法内部都会调用checkXID方法,检查XID文件中的事务状态是否与给定的状态相等;close方法用于关闭文件通道和文件。
XID文件
XID 的定义和规则:
每个事务都有一个唯一的事务标识符 XID,从 1 开始递增,并且 XID 0 被特殊定义为超级事务(Super Transaction)。
XID 0 用于表示在没有申请事务的情况下进行的操作,其状态永远是 committed。
事务的状态:
每个事务可以处于三种状态之一:active(正在进行,尚未结束)、committed(已提交)和aborted(已撤销或回滚)。
XID 文件的结构和管理:
TransactionManager 负责维护一个 XID 格式的文件,用于记录各个事务的状态。
XID 文件中为每个事务分配了一个字节的空间,用来保存其状态。
XID 文件的头部保存了一个 8 字节的数字,记录了这个 XID 文件管理的事务的个数。
因此,事务 XID 在文件中的状态存储在 (XID-1)+8 字节的位置处,其中 XID-1 是因为 XID 0(超级事务)的状态不需要记录。
TM接口 在TransactionManager中提供了一些接口供其他模块调用,用来创建事务和查询事务的状态;
1 2 3 4 5 6 7 8 9 public interface TransactionManager { long begin () ; void commit (long xid) ; void abort (long xid) ; boolean isActive (long xid) ; boolean isCommitted (long xid) ; boolean isAborted (long xid) ; void close () ; }
如何实现TM的? 定义常量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class TransactionManagerImpl implements TransactionManager { static final int LEN_XID_HEADER_LENGTH = 8 ; private static final int XID_FIELD_SIZE = 1 ; private static final byte FIELD_TRAN_ACTIVE = 0 ; private static final byte FIELD_TRAN_COMMITTED = 1 ; private static final byte FIELD_TRAN_ABORTED = 2 ; public static final long SUPER_XID = 0 ; static final String XID_SUFFIX = ".xid" ; }
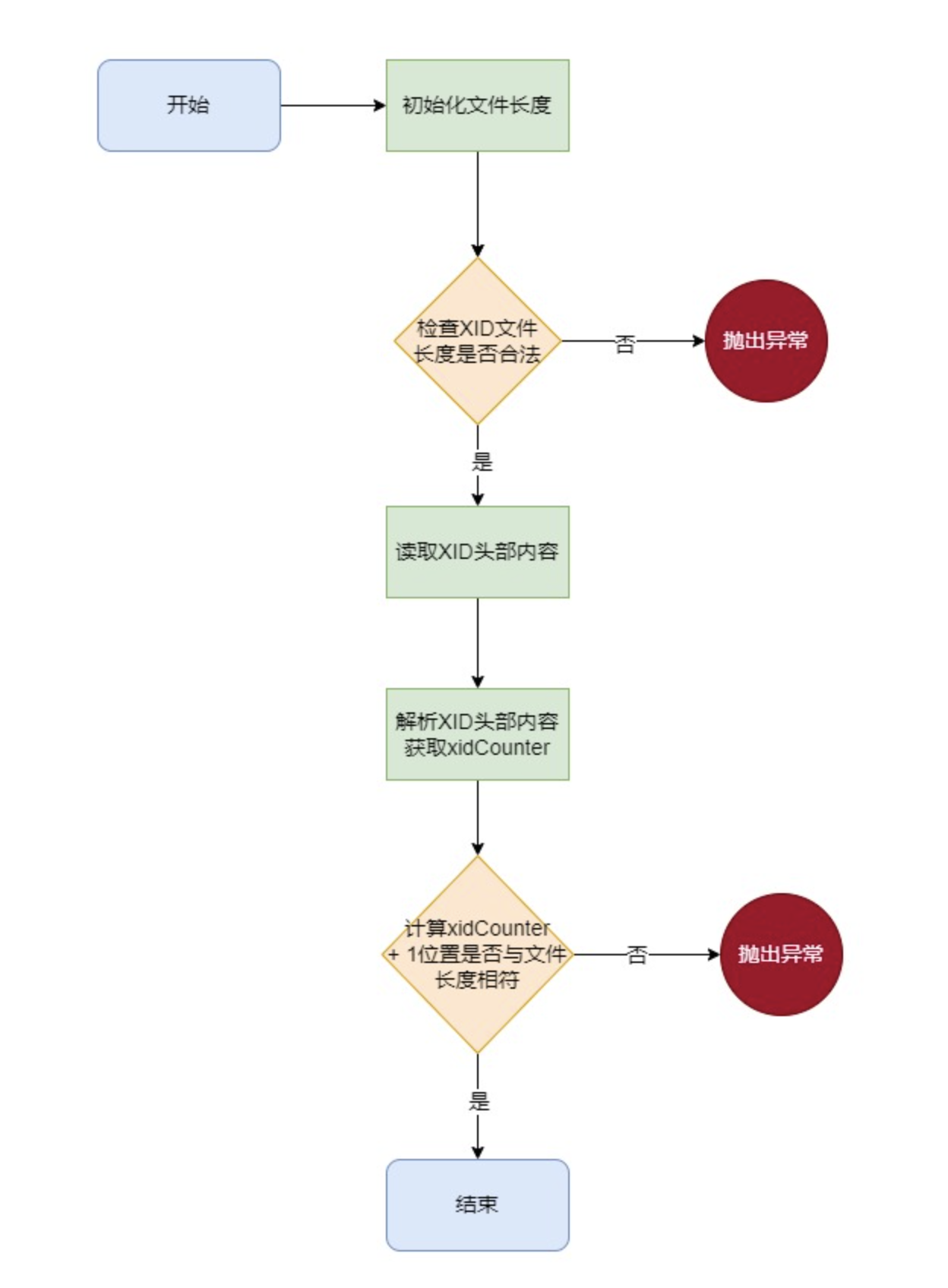
checkXIDCounter 在构造函数创建了一个 TransactionManager 之后,首先要对 XID 文件进行校验,以保证这是一个合法的 XID 文件。校验的方式也很简单,通过文件头的 8 字节数字反推文件的理论长度 ,与文件的实际长度做对比。如果不同则认为 XID 文件不合法。对于校验没有通过的,会直接通过 panic 方法,强制停机。在一些基础模块中出现错误都会如此处理,无法恢复的错误只能直接停机。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 private void checkXIDCounter () { long fileLen = 0 ; try { fileLen = file.length(); } catch (IOException e1) { Panic.panic(Error.BadXIDFileException); } if (fileLen < LEN_XID_HEADER_LENGTH) { Panic.panic(Error.BadXIDFileException); } ByteBuffer buf = ByteBuffer.allocate(LEN_XID_HEADER_LENGTH); try { fc.position(0 ); fc.read(buf); } catch (IOException e) { Panic.panic(e); } this .xidCounter = Parser.parseLong(buf.array()); long end = getXidPosition(this .xidCounter + 1 ); if (end != fileLen) { Panic.panic(Error.BadXIDFileException); } } public static long parseLong (byte [] buf) { ByteBuffer buffer = ByteBuffer.wrap(buf, 0 , 8 ); return buffer.getLong(); } @Test public void testBufferGetLong () { byte [] byteArray = new byte []{0 , 0 , 0 , 0 , 0 , 0 , 10 , 1 }; ByteBuffer buffer = ByteBuffer.wrap(byteArray); long longValue = buffer.getLong(); System.out.println("The long value is: " + longValue); }
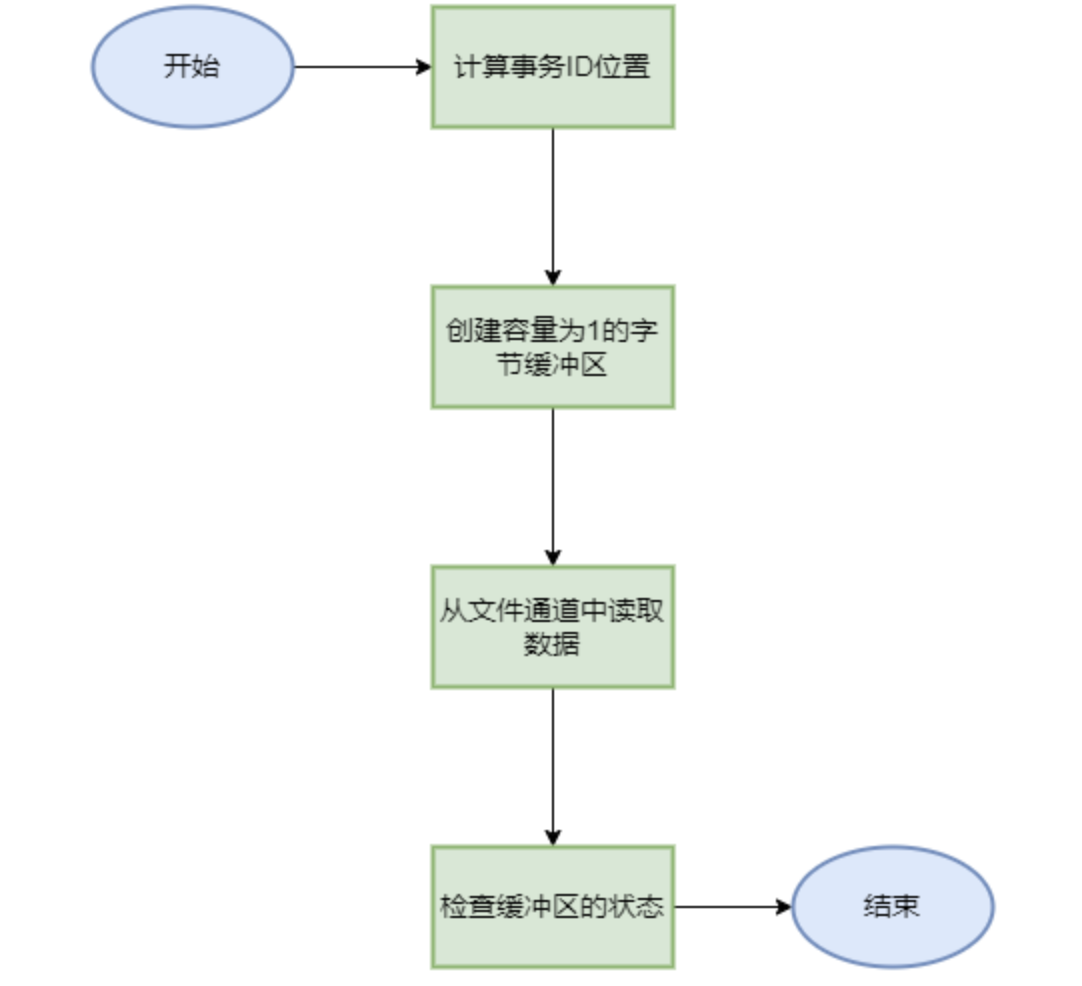
getXidPosition 根据事务xid取得其在xid文件中对应的位置
1 2 3 4 private long getXidPosition (long xid) { return LEN_XID_HEADER_LENGTH + (xid - 1 ) * XID_FIELD_SIZE; }
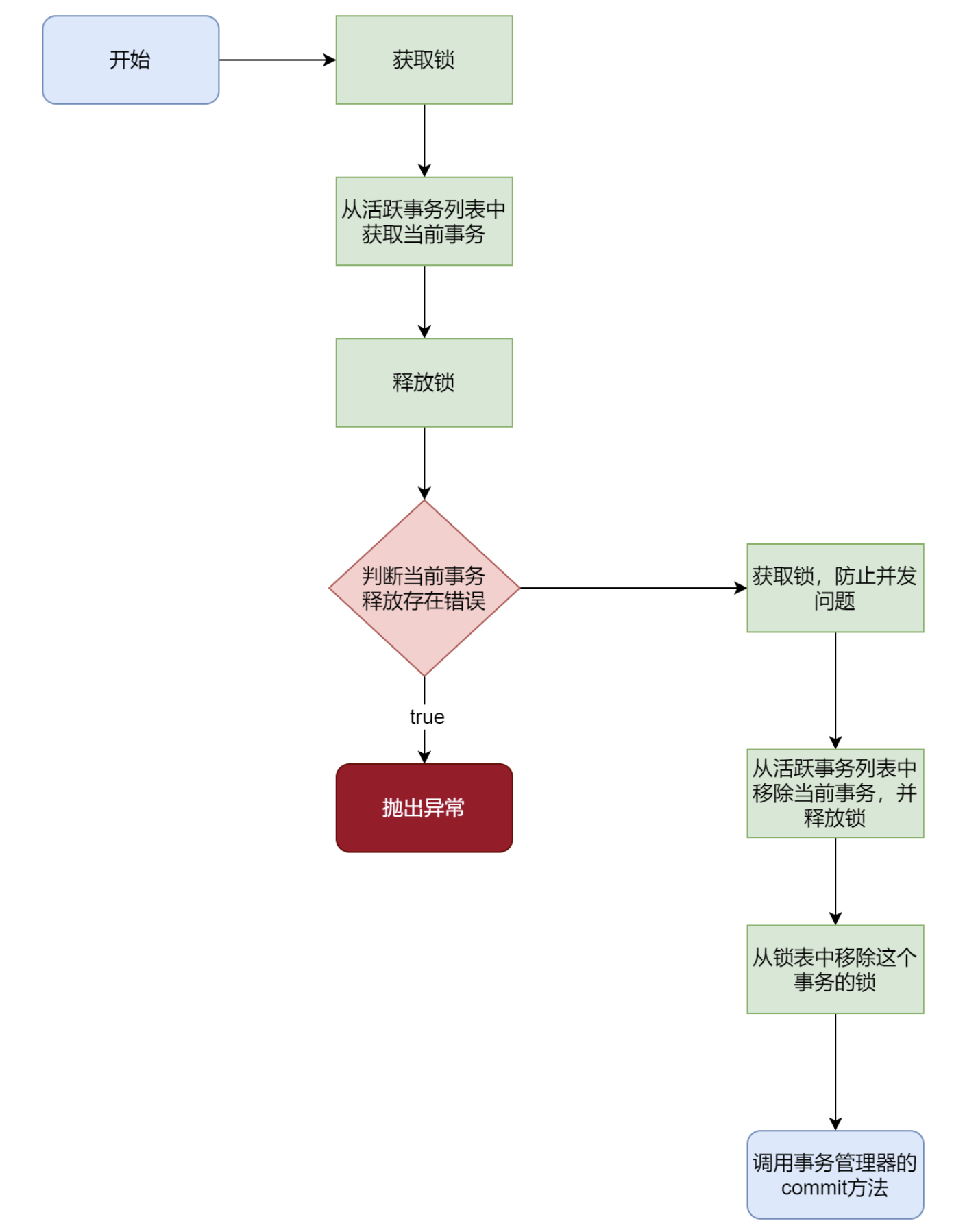
begin() **begin()** 方法会开始一个事务,更具体的,首先设置 xidCounter+1 事务的状态为 active,随后 xidCounter 自增,并更新文件头。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public long begin () { counterLock.lock(); try { long xid = xidCounter + 1 ; updateXID(xid, FIELD_TRAN_ACTIVE); incrXIDCounter(); return xid; } finally { counterLock.unlock(); } }
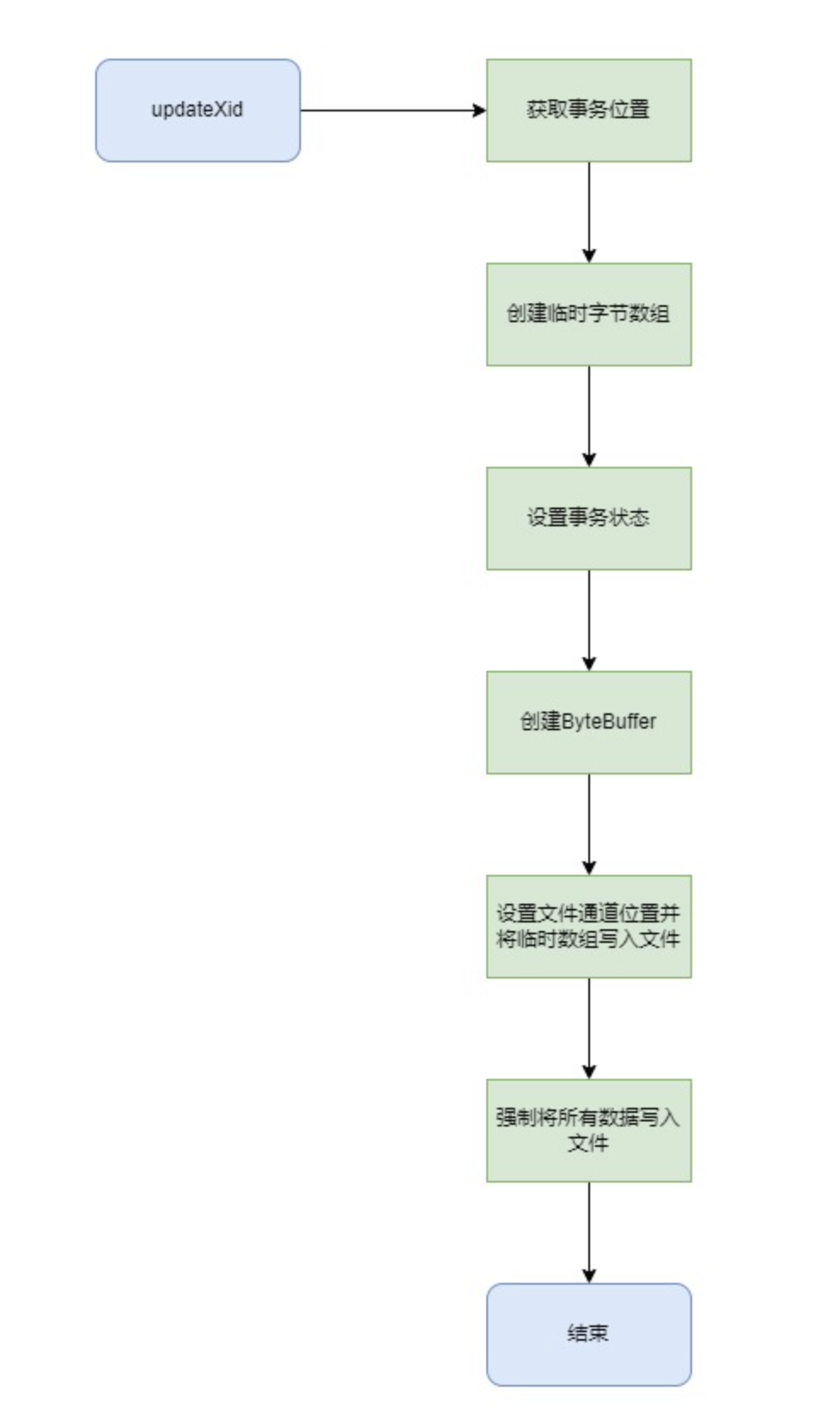
updateXid 更新事务ID状态,commit()和abort()方法就可以直接借助 updateXID() 方法实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private void updateXID (long xid, byte status) { long offset = getXidPosition(xid); byte [] tmp = new byte [XID_FIELD_SIZE]; tmp[0 ] = status; ByteBuffer buf = ByteBuffer.wrap(tmp); try { fc.position(offset); fc.write(buf); } catch (IOException e) { Panic.panic(e); } try { fc.force(false ); } catch (IOException e) { Panic.panic(e); } }
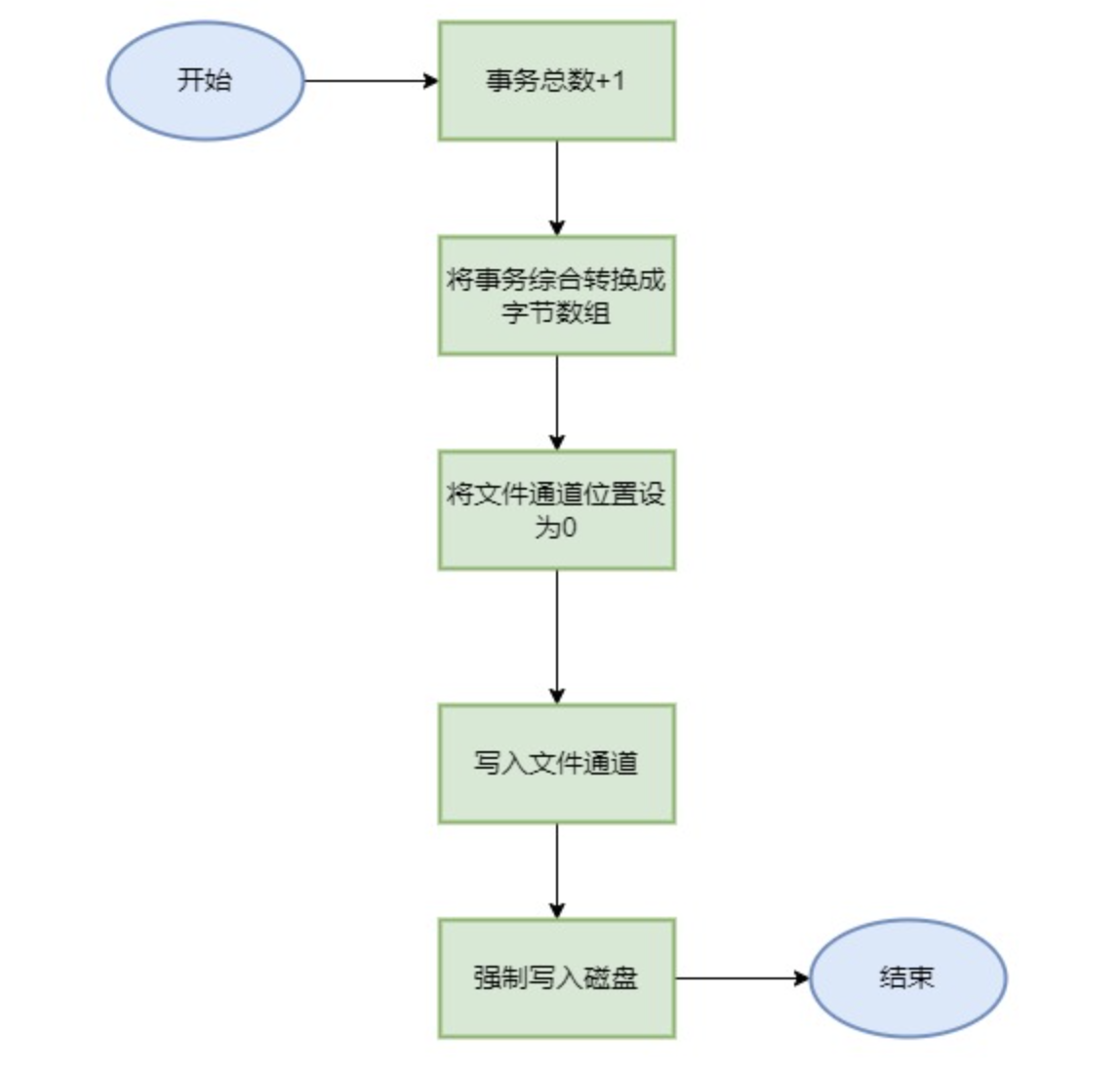
incrXIDCounter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private void incrXIDCounter () { xidCounter++; ByteBuffer buf = ByteBuffer.wrap(Parser.long2Byte(xidCounter)); try { fc.position(0 ); fc.write(buf); } catch (IOException e) { Panic.panic(e); } try { fc.force(false ); } catch (IOException e) { Panic.panic(e); } } public static byte [] long2Byte(long value) { return ByteBuffer.allocate(Long.SIZE / Byte.SIZE).putLong(value).array(); }
checkXID **isActive()、isCommitted() **和 **isAborted()** 都是检查一个 xid 的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private boolean checkXID (long xid, byte status) { long offset = getXidPosition(xid); ByteBuffer buf = ByteBuffer.wrap(new byte [XID_FIELD_SIZE]); try { fc.position(offset); fc.read(buf); } catch (IOException e) { Panic.panic(e); } return buf.array()[0 ] == status; }
Data Manager (DM) 数据管理器 引用计数缓存框架
原文
不回源。由于没法确定缓存被驱逐的时间,更没法确定被驱逐之后数据项是否被修改,这样是极其不安全的
回源。如果数据项被驱逐时的数据和现在又是相同的,那就是一次无效回源
放回缓存里,等下次被驱逐时回源。看起来解决了问题,但是此时缓存已经满了,这意味着你还需要驱逐一个资源才能放进去。这有可能会导致缓存抖动问题
当然我们可以记录下资源的最后修改时间,并且让缓存记录下资源被驱逐的时间。但是……
如无必要,无增实体。 —— 奥卡姆剃刀
引用计数缓存框架是一种通用的缓存策略,与LRU(最近最少使用)相比,它采用了不同的资源管理方式。在引用计数缓存框架中,缓存的释放是由上层模块主动调用释放方法来触发的 ,而不是被动地由缓存管理器自动驱逐。当某个资源不再被上层模块引用时,通过调用释放方法来释放对该资源的引用。只有当资源的引用计数归零时,缓存才会驱逐该资源。这种方式可以确保缓存中的资源只有在确实不再被使用时才会被释放,避免了不必要的资源驱逐和回源操作 。
回溯 回源操作 通常指的是从磁盘或者其他持久化存储介质中重新加载数据到内存中。这通常发生在数据库系统需要访问的数据不在内存中时。由于内存访问速度远高于磁盘访问速度,数据库系统会尽量将数据保留在内存中以提高访问速度。当需要访问的数据不在内存中时,数据库系统就需要从磁盘中加载数据,这个过程就称为回源操作。
如何实现引用计数缓存 AbstractCache<T>在**common**包中定义了一个AbstractCache<T>抽象类,以及两个抽象方法,留给实现类去实现具体的操作;
1 2 3 4 5 6 7 8 protected abstract T getForCache (long key) throws Exception;protected abstract void releaseForCache (T obj) ;
引用计数 除了普通的缓存功能之外,还需要维护另外一个计数。除此之外,为了应付多线程的场景,还需要记录哪些资源从数据源获取中。
private HashMap<Long, T> cache;:这是一个 HashMap 对象,用于存储实际缓存的数据。键是资源的唯一标识符(通常是资源的ID或哈希值),值是缓存的资源对象(类型为 T )。在这个缓存框架中,cache 承担了普通缓存功能,即存储实际的资源数据。private HashMap<Long, Integer> references;:这是另一个 HashMap 对象,用于记录每个资源的引用个数。键是资源的唯一标识符,值是一个整数,表示该资源当前的引用计数。引用计数表示有多少个模块或线程正在使用特定的资源。通过跟踪引用计数,可以确定何时可以安全地释放资源。private HashMap<Long, Boolean> getting;:这是第三个 HashMap 对象,用于记录哪些资源当前正在从数据源获取中。键是资源的唯一标识符,值是一个布尔值,表示该资源是否正在被获取中。在多线程环境下,当某个线程尝试从数据源获取资源时,需要标记该资源正在被获取,以避免其他线程重复获取相同的资源。这个 getting 映射用于处理多线程场景下的并发访问问题。1 2 3 private HashMap<Long, T> cache; private HashMap<Long, Integer> references; private HashMap<Long, Boolean> getting;
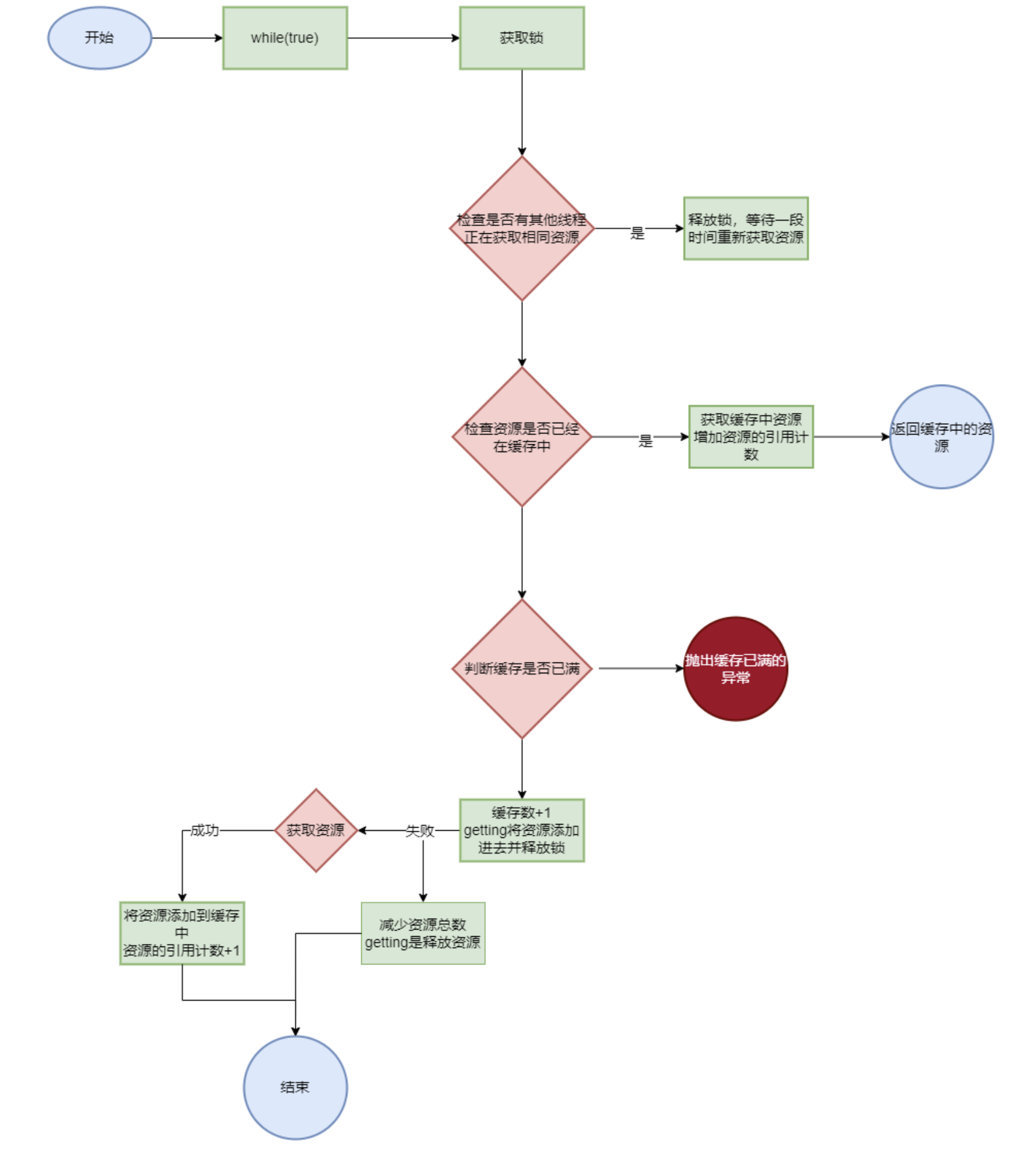
get()从get()中获取资源,以下流程图不规范,理解大概意思即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 protected T get (long key) throws Exception { while (true ) { lock.lock(); if (getting.containsKey(key)) { lock.unlock(); try { Thread.sleep(1 ); } catch (InterruptedException e) { e.printStackTrace(); continue ; } continue ; } if (cache.containsKey(key)) { T obj = cache.get(key); references.put(key, references.get(key) + 1 ); lock.unlock(); return obj; } if (maxResource > 0 && count == maxResource) { lock.unlock(); throw Error.CacheFullException; } count++; getting.put(key, true ); lock.unlock(); break ; } T obj = null ; try { obj = getForCache(key); } catch (Exception e) { lock.lock(); count--; getting.remove(key); lock.unlock(); throw e; } lock.lock(); getting.remove(key); cache.put(key, obj); references.put(key, 1 ); lock.unlock(); return obj; }
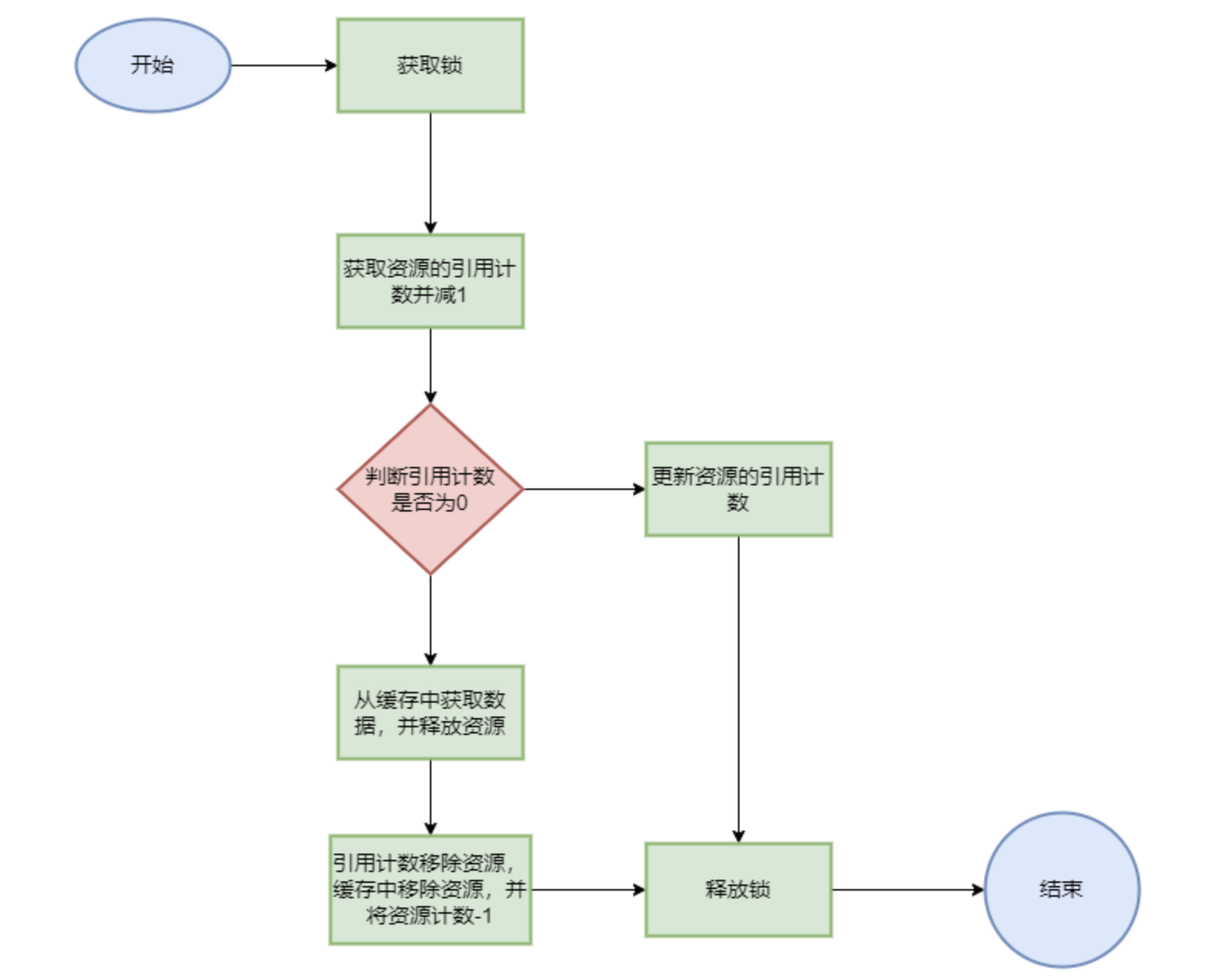
release()释放一个缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 protected void release (long key) { lock.lock(); try { int ref = references.get(key) - 1 ; if (ref == 0 ) { T obj = cache.get(key); releaseForCache(obj); references.remove(key); cache.remove(key); count--; } else { references.put(key, ref); } } finally { lock.unlock(); } }
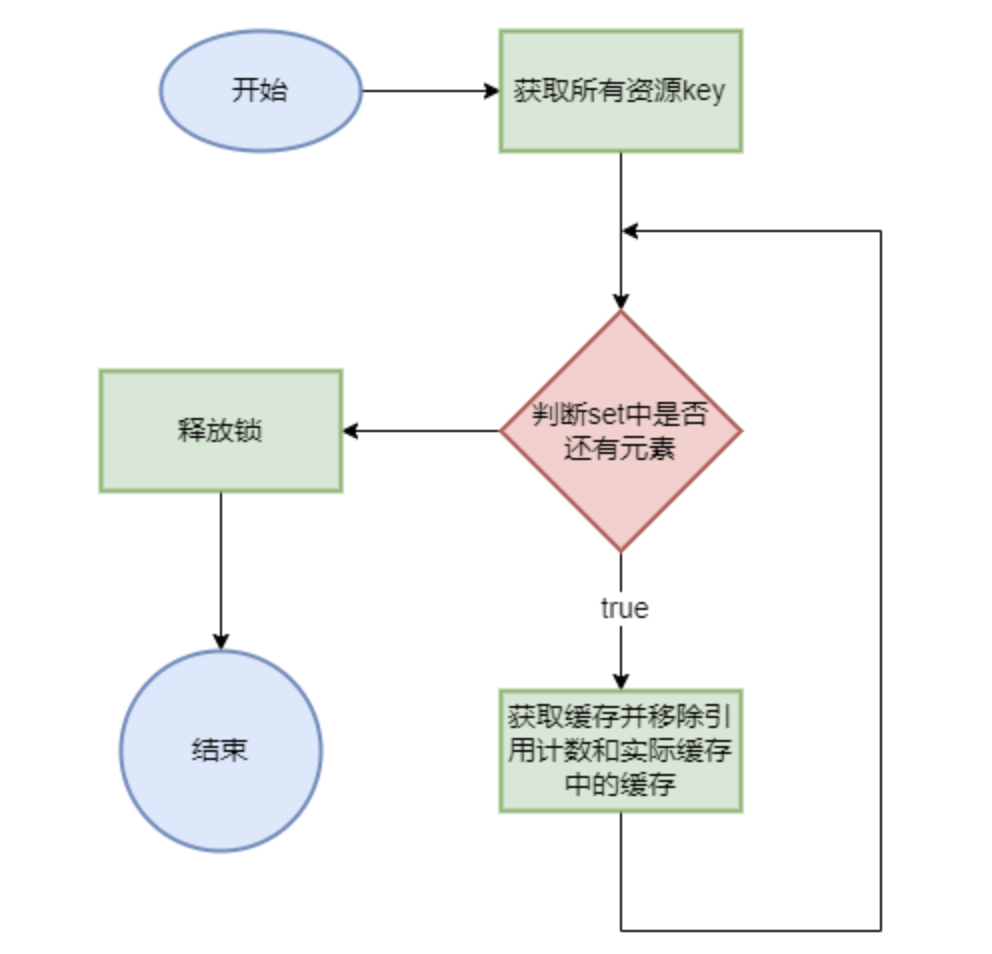
close()关闭缓存,释放所有缓存信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 protected void close () { lock.lock(); try { Set<Long> keys = cache.keySet(); for (long key : keys) { T obj = cache.get(key); releaseForCache(obj); references.remove(key); cache.remove(key); } } finally { lock.unlock(); } }
共享内存数组 原文 这里得提一个 Java 很蛋疼的地方。
1 2 var array1 [10 ]int64 array2 := array1[5 :]
Copy
1 2 3 4 5 6 7 8 9 10 11 12 public class SubArray { public byte [] raw; public int start; public int end; public SubArray (byte [] raw, int start, int end) { this .raw = raw; this .start = start; this .end = end; } }
演示 因为这个数组没啥讲的,通过案例进行演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 @Test public void testSubArray () { byte [] subArray = new byte [10 ]; for (int i = 0 ; i < subArray.length; i++) { subArray[i] = (byte ) (i+1 ); } SubArray sub1 = new SubArray (subArray,3 ,7 ); SubArray sub2 = new SubArray (subArray,6 ,9 ); sub1.raw[4 ] = (byte )44 ; System.out.println("Original Array: " ); printArray(subArray); System.out.println("SubArray1: " ); printSubArray(sub1); System.out.println("SubArray2: " ); printSubArray(sub2); } private void printArray (byte [] array) { System.out.println(Arrays.toString(array)); } private void printSubArray (SubArray subArray) { for (int i = subArray.start; i <= subArray.end; i++) { System.out.print(subArray.raw[i] + "\t" ); } System.out.println(); } -------------------------演示结果---------------------------- Original Array: [1 , 2 , 3 , 4 , 44 , 6 , 7 , 8 , 9 , 10 ] SubArray1: 4 44 6 7 8 SubArray2: 7 8 9 10
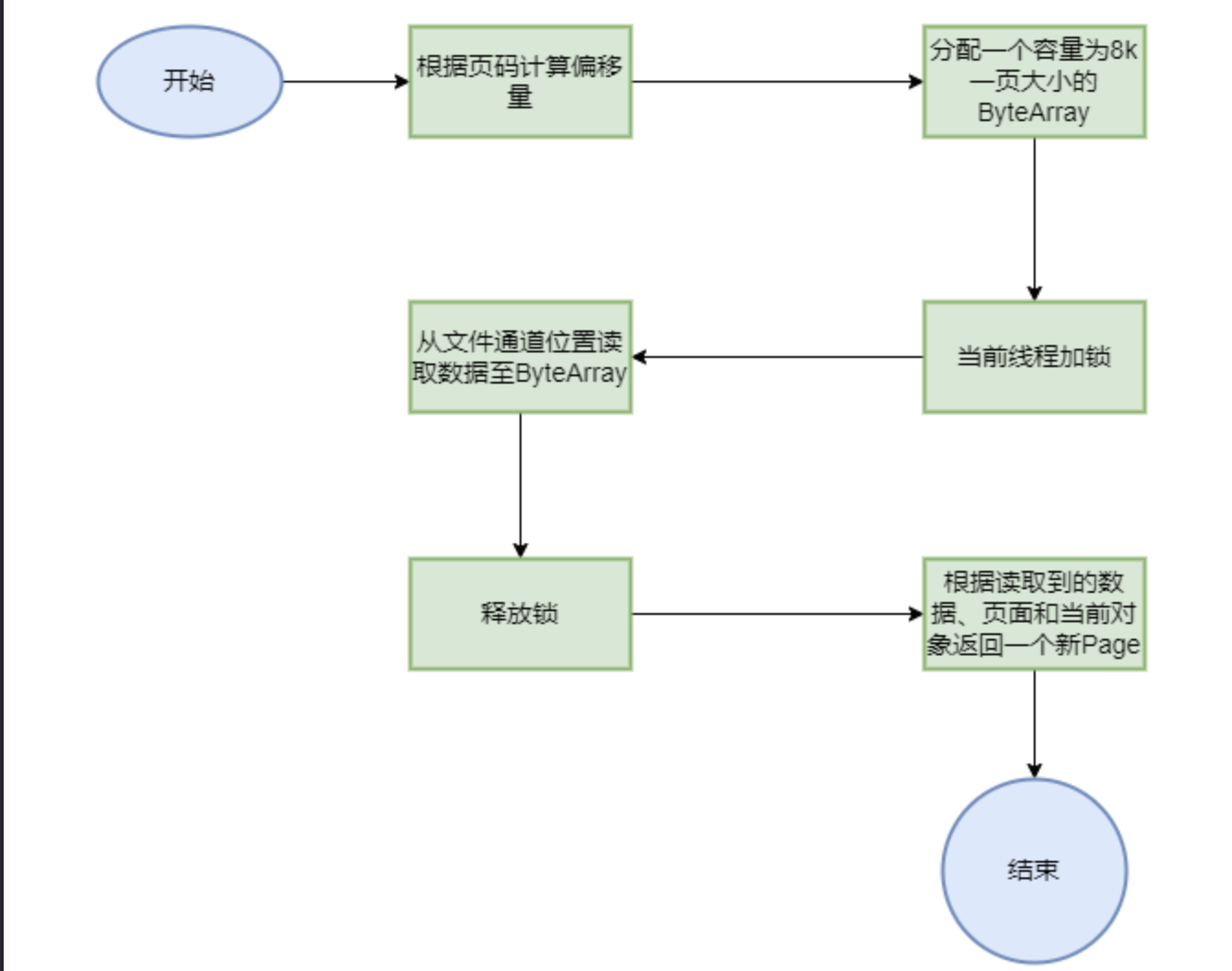
数据页的缓存和管理 本节主要内容就是 DM 模块向下对文件系统的抽象部分。DM 将文件系统抽象成页面,每次对文件系统的读写都是以页面为单位的。同样,从文件系统读进来的数据也是以页面为单位进行缓存的。
这里参考大部分数据库的设计,将默认数据页大小定为 8K。如果想要提升向数据库写入大量数据情况下的性能的话,也可以适当增大这个值。
上一节我们已经实现了一个通用的缓存框架,那么这一节我们需要缓存页面,就可以直接借用那个缓存的框架了。但是首先,需要定义出页面的结构。注意这个页面是存储在内存中的 ,与已经持久化到磁盘的抽象页面有区别。
数据库中实现页面缓存的相关设计和实现。
页面结构定义 :
页面(Page)是存储在内存中的数据单元,其结构包括:
pageNumber:页面的页号,从1 开始计数。
data:实际包含的字节数据。
dirty:标志着页面是否是脏页面,在缓存驱逐时,脏页面需要被写回磁盘。
lock:用于页面的锁。
PageCache:保存了一个 PageCache 的引用,方便在拿到 Page 的引用时可以快速对页面的缓存进行释放操作。
1 2 3 4 5 6 7 public class PageImpl implements Page { private int pageNumber; private byte [] data; private boolean dirty; private Lock lock; private PageCache pc; }
页面缓存接口定义 :
定义了页面缓存的接口,包括新建页面、获取页面、释放页面、关闭缓存、根据最大页号截断缓存、获取当前页面数量以及刷新页面等方法。1 2 3 4 5 6 7 8 9 10 public interface PageCache { int newPage (byte [] initData) ; Page getPage (int pgno) throws Exception; void close () ; void release (Page page) ; void truncateByBgno (int maxPgno) ; int getPageNumber () ; void flushPage (Page pg) ; }
页面缓存实现 :
页面缓存的具体实现类需要继承抽象缓存框架,并实现具体的 getForCache() 和 releaseForCache() 方法。
getForCache() 方法用于从文件中读取页面数据,并将其包裹成 Page 返回。
releaseForCache() 方法用于在驱逐页面时决定是否将脏页面写回到文件系统。
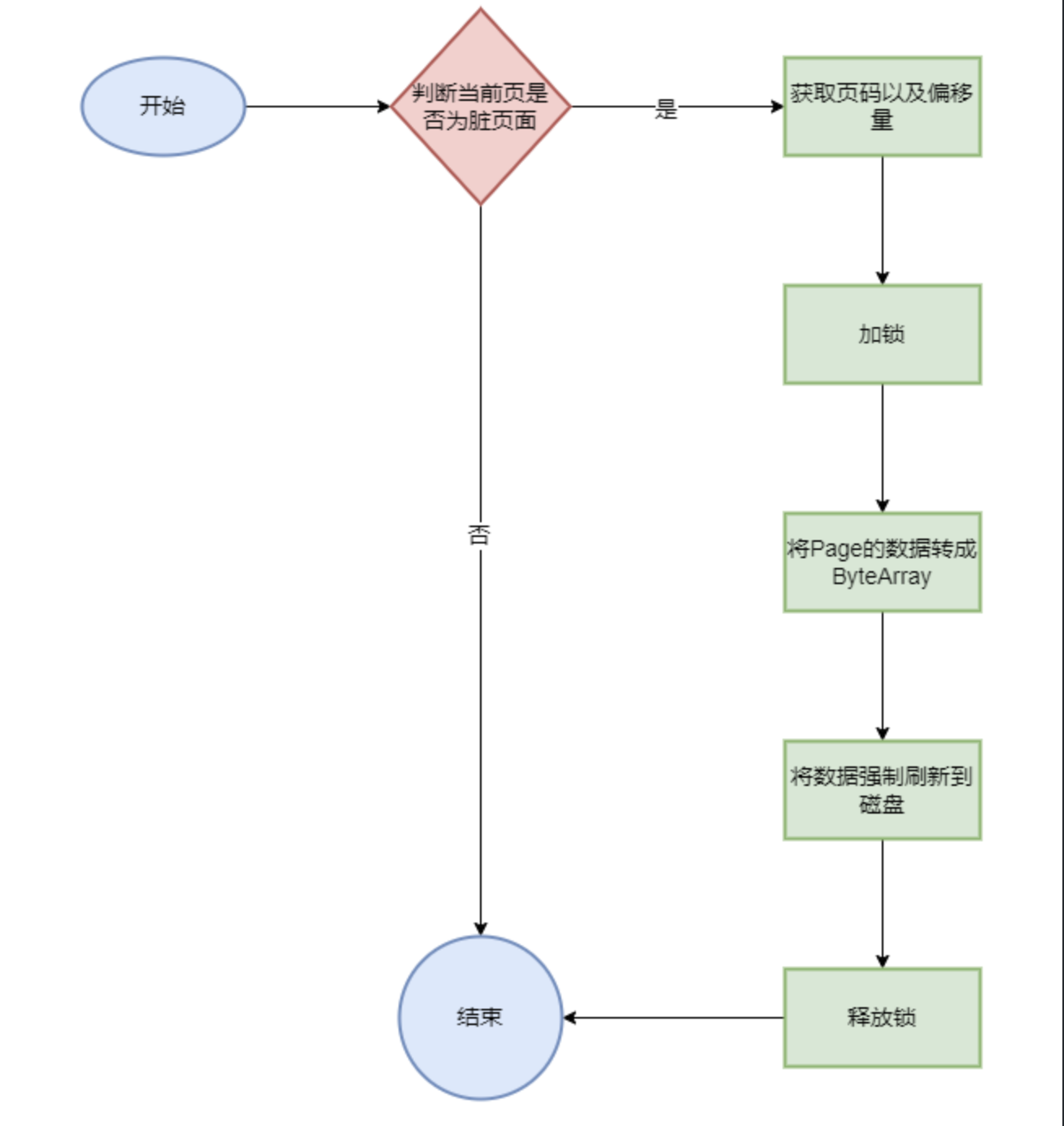
页面写回文件系统 :
页面缓存在驱逐页面时,根据页面是否是脏页面决定是否将其写回到文件系统。
写回操作使用文件锁来保证写入的原子性和线程安全性。
新建页面 :
新建页面时,页面缓存会自增页面数量,并在写入文件系统后返回新建页面的页号。1 2 3 4 5 6 7 8 9 public int newPage (byte [] initData) { int pgno = pageNumbers.incrementAndGet(); Page pg = new PageImpl (pgno, initData, null ); flush(pg); return pgno; }
限制条件 :
数据库中不允许同一条数据跨页存储,即单条数据的大小不能超过数据库页面的大小。
getForCache()获取数据页的页面缓存,并将其包裹成Page
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Override protected Page getForCache (long key) throws Exception { int pgno = (int ) key; long offset = PageCacheImpl.pageOffset(pgno); ByteBuffer buf = ByteBuffer.allocate(PAGE_SIZE); fileLock.lock(); try { fc.position(offset); fc.read(buf); } catch (IOException e) { Panic.panic(e); } fileLock.unlock(); return new PageImpl (pgno, buf.array(), this ); } public PageImpl (int pageNumber, byte [] data, PageCache pc) { this .pageNumber = pageNumber; this .data = data; this .pc = pc; lock = new ReentrantLock (); }
releaseForCache() 当一个Page对象(页面)不再需要在缓存中保留时,就会调用这个方法。如果这个页面被标记为”dirty”(即,这个页面的内容已经被修改,但还没有写回到磁盘),那么这个方法就会调用flush方法,将这个页面的内容写回到磁盘。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override protected void releaseForCache (Page pg) { if (pg.isDirty()) { flush(pg); pg.setDirty(false ); } } private void flush (Page pg) { int pgno = pg.getPageNumber(); long offset = pageOffset(pgno); fileLock.lock(); try { ByteBuffer buf = ByteBuffer.wrap(pg.getData()); fc.position(offset); fc.write(buf); fc.force(false ); } catch (IOException e) { Panic.panic(e); } finally { fileLock.unlock(); } }
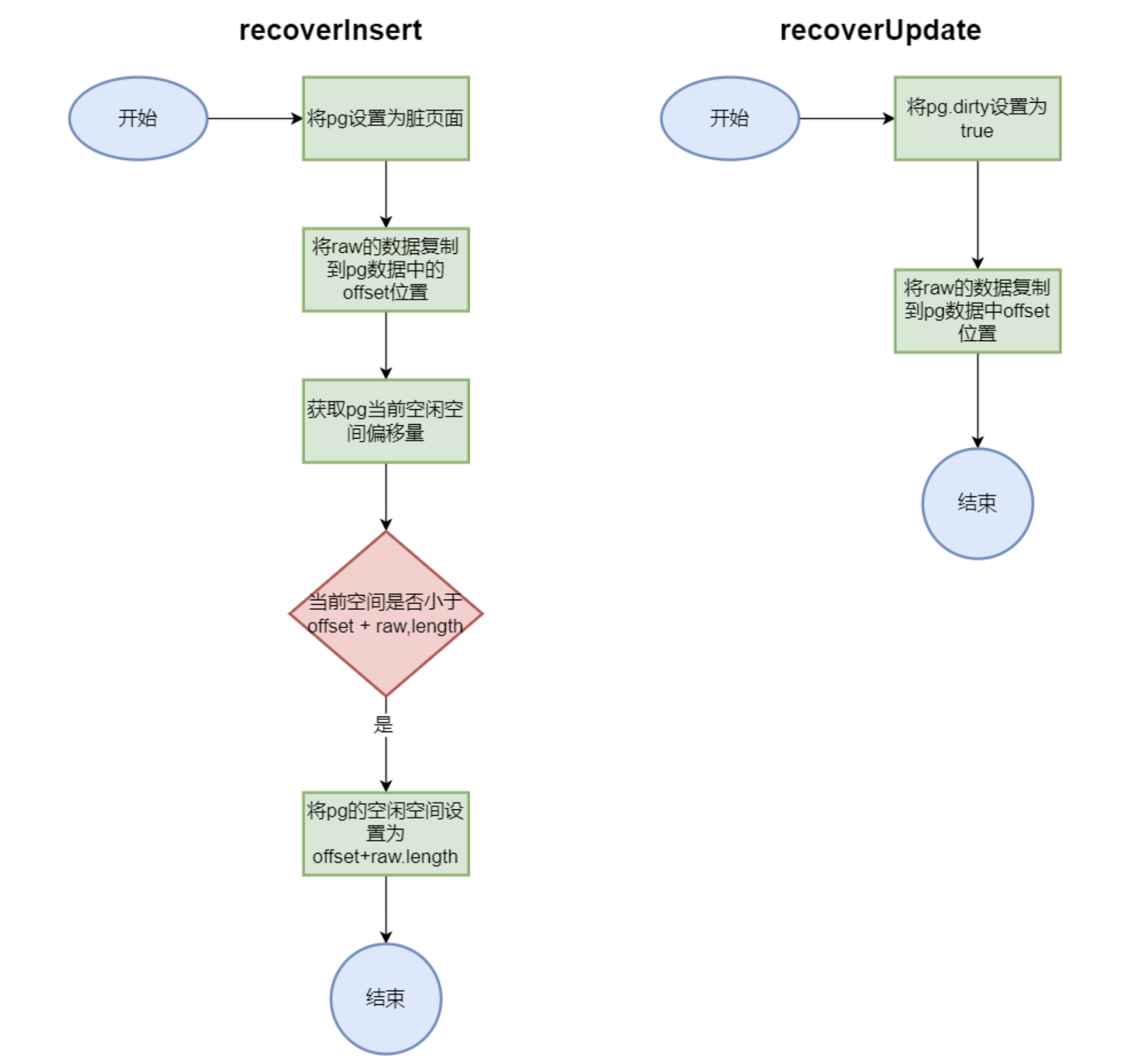
recoverInsert()和recoverUpdate()** recoverInsert() **和 **recoverUpdate()** 用于在数据库崩溃后重新打开时,恢复例程直接插入数据以及修改数据使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void recoverInsert (Page pg, byte [] raw, short offset) { pg.setDirty(true ); System.arraycopy(raw, 0 , pg.getData(), offset, raw.length); short rawFSO = getFSO(pg.getData()); if (rawFSO < offset + raw.length) { setFSO(pg.getData(), (short ) (offset + raw.length)); } } public static void recoverUpdate (Page pg, byte [] raw, short offset) { pg.setDirty(true ); System.arraycopy(raw, 0 , pg.getData(), offset, raw.length); }
数据页的管理 第一页 数据库文件的第一个,用与做一些特殊用途,比如存储一些元数据,用于启动检查等。在MYDB 中的第一页,只是用来做启动检查。
每次数据库启动时,会生成一串随机字节,存储在 100~107 字节
在正常数据库关闭时,会将这串字节拷贝到第一页的 108~115 字节
数据库每次启动时,都会检查第一页两处的字节是否相同;用来判断上次是否正常关闭,是否需要进行数据的恢复流程
启动初始化字节 1 2 3 4 5 6 7 8 9 10 public static void setVcOpen (Page pg) { pg.setDirty(true ); setVcOpen(pg.getData()); } private static void setVcOpen (byte [] raw) { System.arraycopy(RandomUtil.randomBytes(LEN_VC), 0 , raw, OF_VC, LEN_VC); }
关闭时拷贝字节 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void setVcClose (Page pg) { pg.setDirty(true ); setVcClose(pg.getData()); } private static void setVcClose (byte [] raw) { System.arraycopy(raw, OF_VC, raw, OF_VC + LEN_VC, LEN_VC); }
校验字节 1 2 3 4 5 6 7 8 9 10 public static boolean checkVc (Page pg) { return checkVc(pg.getData()); } private static boolean checkVc (byte [] raw) { return Arrays.equals(Arrays.copyOfRange(raw, OF_VC, OF_VC + LEN_VC), Arrays.copyOfRange(raw, OF_VC + LEN_VC, OF_VC + 2 * LEN_VC)); }
普通页 一个普通页面是以 2字节无符号数起始,因为一个页面最大容量为 8k,而二字节的范围是 0到2^16-1,所以2字节作为初始完全足够表达这一页空闲位置的偏移量。**FSO(Free Space Offset)**进行管理的;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private static void setFSO (byte [] raw, short ofData) { System.arraycopy(Parser.short2Byte(ofData), 0 , raw, OF_FREE, OF_DATA); } public static short getFSO (Page pg) { return getFSO(pg.getData()); } private static short getFSO (byte [] raw) { return Parser.parseShort(Arrays.copyOfRange(raw, 0 , 2 )); } public static int getFreeSpace (Page pg) { return PageCache.PAGE_SIZE - (int ) getFSO(pg.getData()); }
insert()1 2 3 4 5 6 7 8 public static short insert (Page pg, byte [] raw) { pg.setDirty(true ); short offset = getFSO(pg.getData()); System.arraycopy(raw, 0 , pg.getData(), offset, raw.length); setFSO(pg.getData(), (short ) (offset + raw.length)); return offset; }
日志文件 MYDB提供了崩溃后的数据恢复功能,DM层在每次对底层数据进行操作时,都会记录一条日志到磁盘上。在数据库崩溃之后,再次重启时,可以根据日志的内容,恢复数据文件,保证其一致性;
日志读写 日志的二进制文件,按照如下的格式进行排布:
1 [XChecksum][Log1][Log2][Log3]...[LogN][BadTail]
其中 **XChecksum** 是一个四字节的整数,是对后续所有日志计算的校验和。**Log1 ~ LogN** 是常规的日志数据,**BadTail** 是在数据库崩溃时,没有来得及写完的日志数据,这个 **BadTail** 不一定存在。
1 2 3 4 [Size][Checksum][Data] [0, 0, 0, 3] [3, -112, -4, 93] [97, 97, 97] [0, 0, 0, 3] [14, 40, -23, -38] [98, 98, 98] [0, 0, 0, 3] [24, -64, -41, 87] [99, 99, 99]
其中,**Size** 是一个四字节整数,标识了 **Data** 段的字节数。**Checksum** 则是该条日志的校验和。单条文件的校验和
1 2 3 4 5 6 private int calChecksum (int xCheck, byte [] log) { for (byte b : log) { xCheck = xCheck * SEED + b; } return xCheck; }
日志文件的创建及初始化 create()会初始化 [XChecksum] 的字节大小,默认为0;
1 2 3 4 5 6 7 8 9 ByteBuffer buf = ByteBuffer.wrap(Parser.int2Byte(0 )); try { fc.position(0 ); fc.write(buf); fc.force(false ); } catch (IOException e) { Panic.panic(e); }
日志文件创建完需要打开时,会调用open()方法,并读取日志文件的[XChecksum]以及去除BadTail;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void init () { long size = 0 ; try { size = file.length(); } catch (IOException e) { Panic.panic(e); } if (size < 4 ) { Panic.panic(Error.BadLogFileException); } ByteBuffer raw = ByteBuffer.allocate(4 ); try { fc.position(0 ); fc.read(raw); } catch (IOException e) { Panic.panic(e); } int xChecksum = Parser.parseInt(raw.array()); this .fileSize = size; this .xChecksum = xChecksum; checkAndRemoveTail(); }
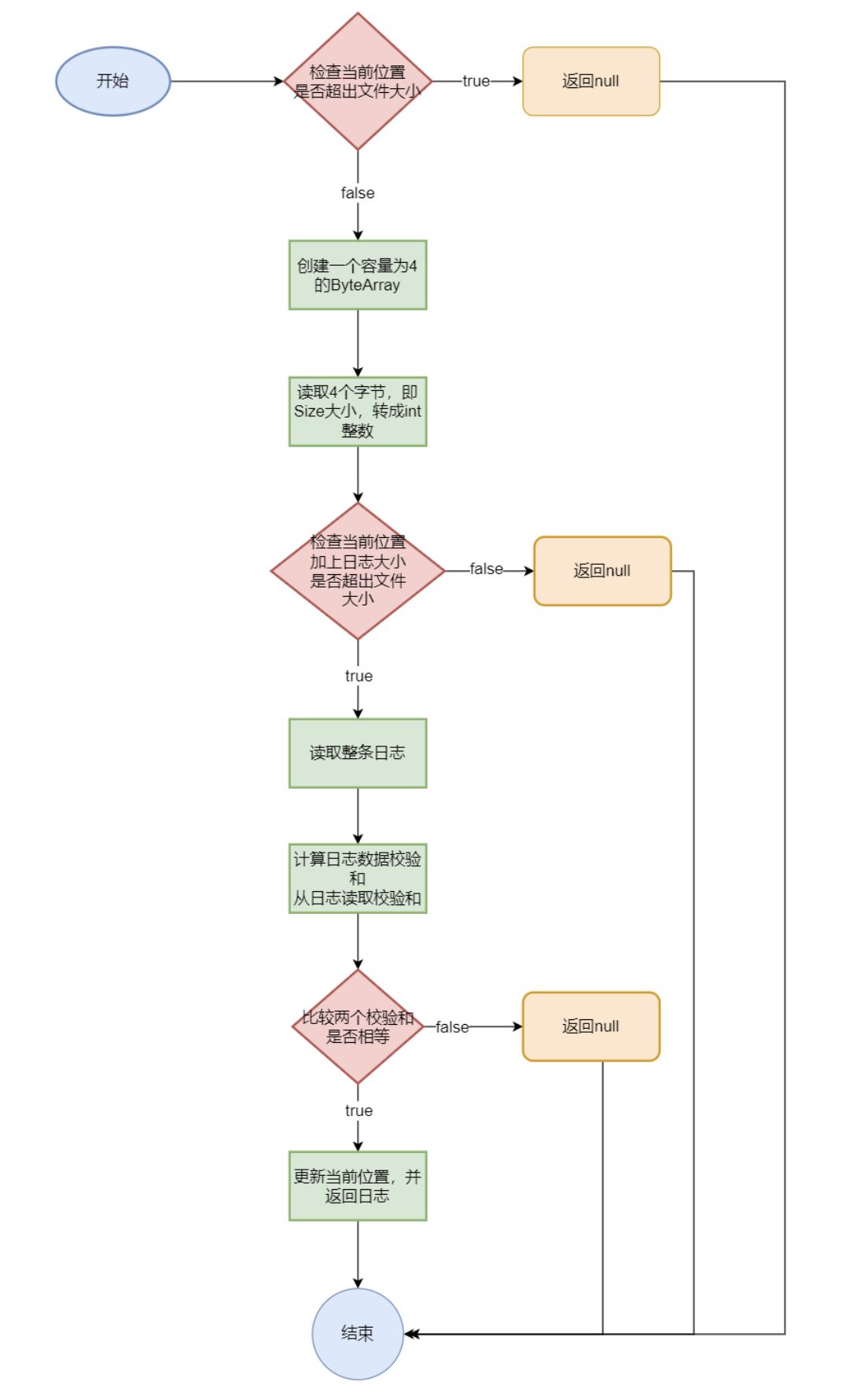
internNext()画的不规范,大概意思知道即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 private byte [] internNext() { if (position + OF_DATA >= fileSize) { return null ; } ByteBuffer tmp = ByteBuffer.allocate(4 ); try { fc.position(position); fc.read(tmp); } catch (IOException e) { Panic.panic(e); } int size = Parser.parseInt(tmp.array()); if (position + size + OF_DATA > fileSize) { return null ; } ByteBuffer buf = ByteBuffer.allocate(OF_DATA + size); try { fc.position(position); fc.read(buf); } catch (IOException e) { Panic.panic(e); } byte [] log = buf.array(); int checkSum1 = calChecksum(0 , Arrays.copyOfRange(log, OF_DATA, log.length)); int checkSum2 = Parser.parseInt(Arrays.copyOfRange(log, OF_CHECKSUM, OF_DATA)); if (checkSum1 != checkSum2) { return null ; } position += log.length; return log; }
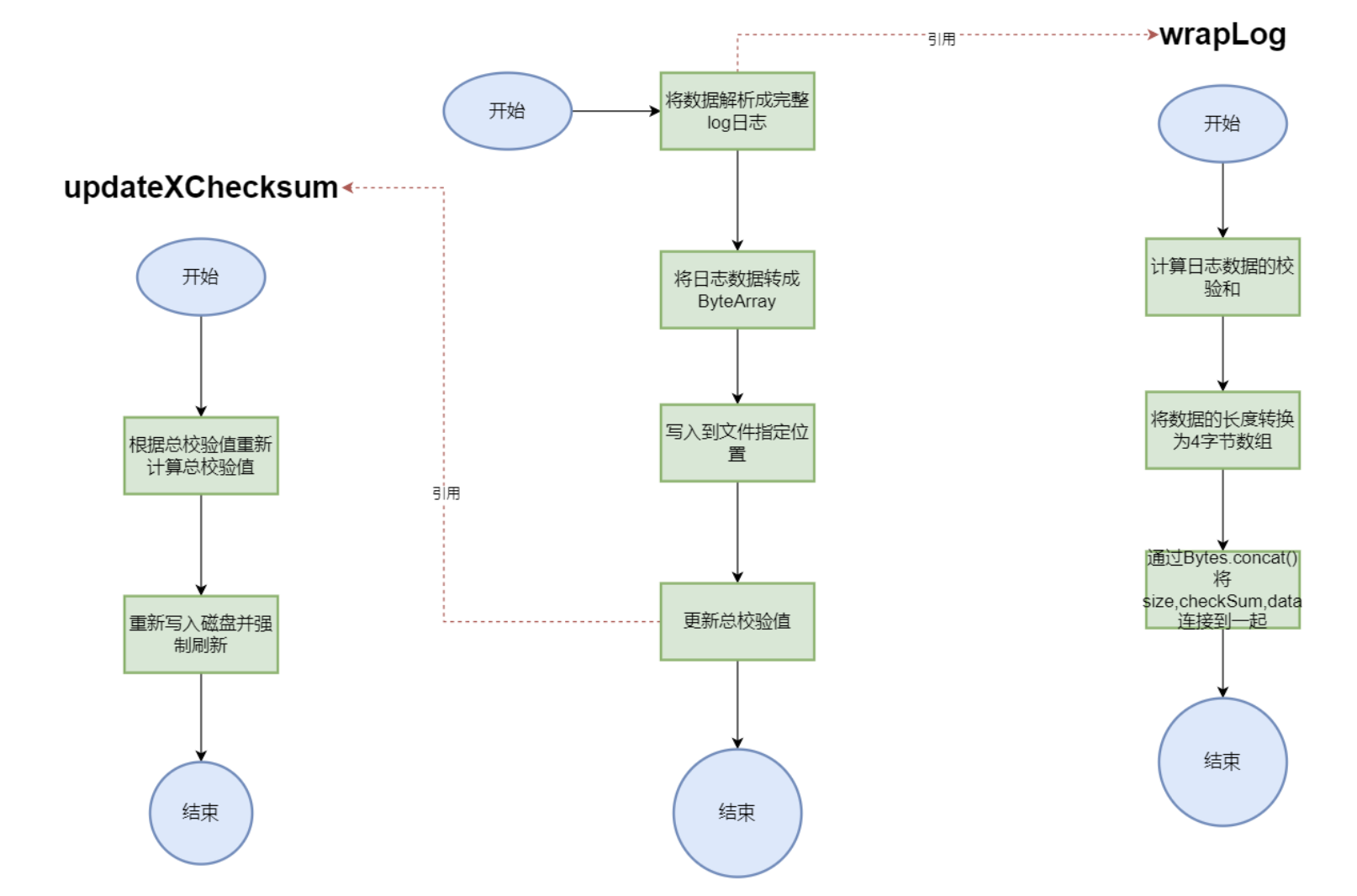
log()向日志文件写入日志时,也是首先将数据包裹成日志格式,写入文件后,再更新文件的校验和,更新校验和时,会刷新缓冲区,保证内容写入磁盘。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @Override public void log (byte [] data) { byte [] log = wrapLog(data); ByteBuffer buf = ByteBuffer.wrap(log); lock.lock(); try { fc.position(fc.size()); fc.write(buf); } catch (IOException e) { Panic.panic(e); } finally { lock.unlock(); } updateXChecksum(log); } private void updateXChecksum (byte [] log) { this .xChecksum = calChecksum(this .xChecksum, log); try { fc.position(0 ); fc.write(ByteBuffer.wrap(Parser.int2Byte(xChecksum))); fc.force(false ); } catch (IOException e) { Panic.panic(e); } } private byte [] wrapLog(byte [] data) { byte [] checksum = Parser.int2Byte(calChecksum(0 , data)); byte [] size = Parser.int2Byte(data.length); return Bytes.concat(size, checksum, data); }
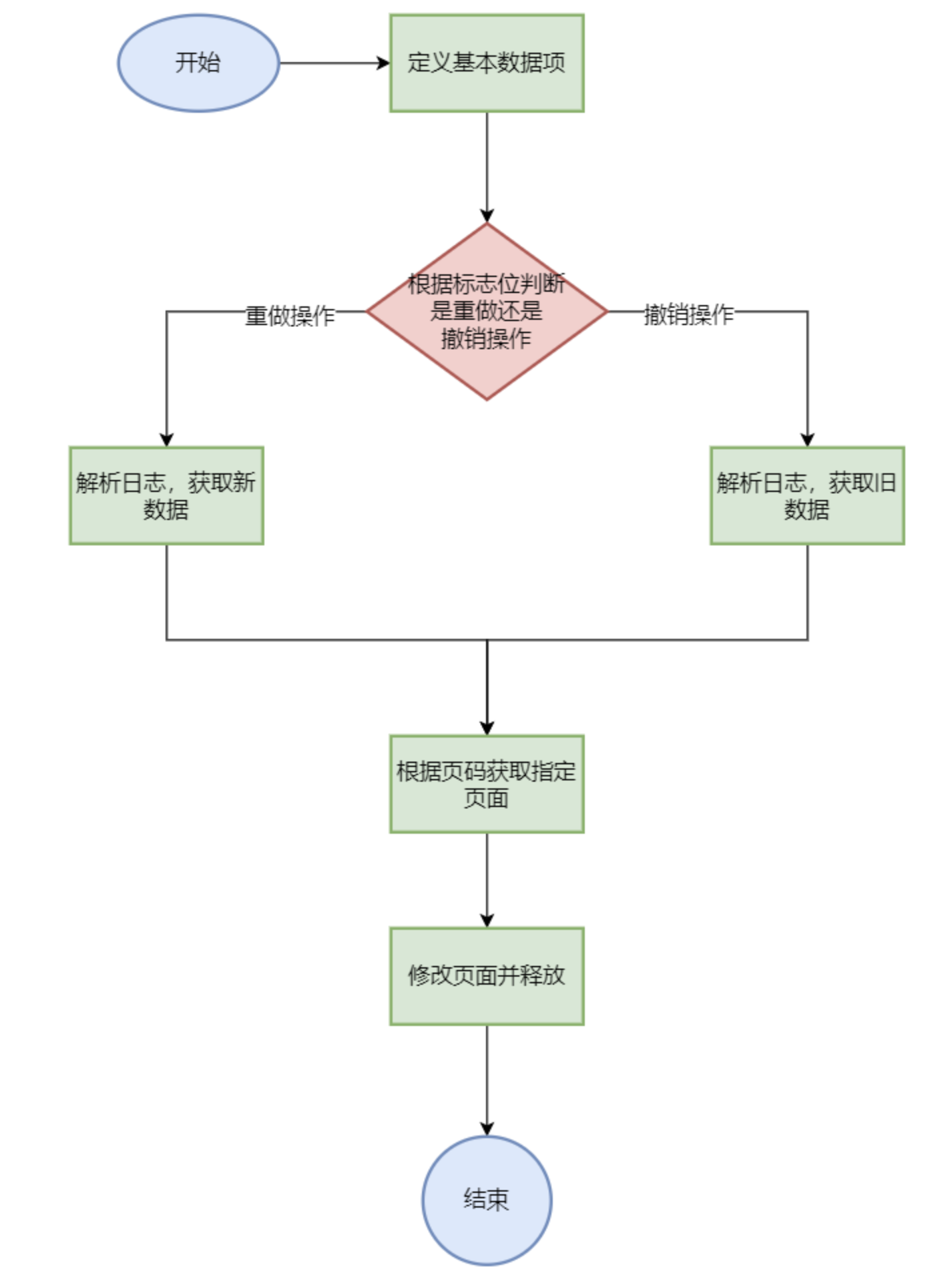
恢复策略 在MYDB中,有两条规则限制了数据库的操作,以便于恢复日志;
正在进行的事务,不会读取其他任何未提交的事务产生的数据 正在进行的事务,不会修改其他任何未提交的事务修改或产生的数据
根据上方的两条规则,MYDB日志的恢复也分为两种:
通过 **redo log**重做所有崩溃时已经完成( **committed 或 aborted**)的事务 通过 **undo log**撤销所有崩溃时未完成( **active****)的事务 **
redo:
正序扫描事务 T 的所有日志
如果日志是插入操作 (Ti, I, A, x),就将 x 重新插入 A 位置
如果日志是更新操作 (Ti, U, A, oldx, newx),就将 A 位置的值设置为 newx
undo:
倒序扫描事务 T 的所有日志
如果日志是插入操作 (Ti, I, A, x),就将 A 位置的数据删除
如果日志是更新操作 (Ti, U, A, oldx, newx),就将 A 位置的值设置为 oldx
注:对于 redo log 和 undo log,可以学习该文章(图解MySQL-日志篇 )
日志格式
1 2 3 4 5 6 7 8 9 10 public class Recover { private static final byte LOG_TYPE_INSERT = 0 ; private static final byte LOG_TYPE_UPDATE = 1 ; }
重做所有已完成的事务 redo log
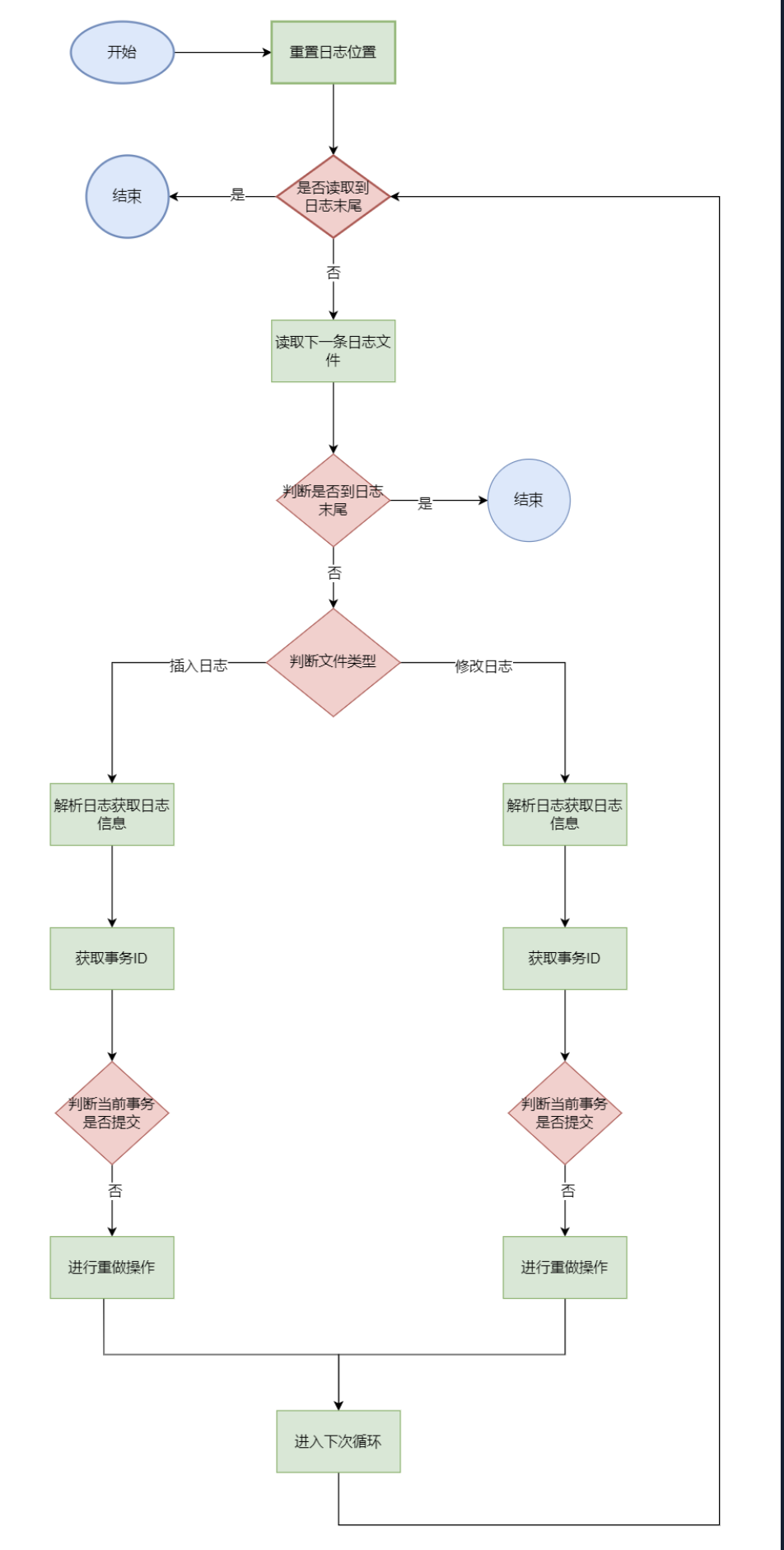
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private static void redoTranscations (TransactionManager tm, Logger lg, PageCache pc) { lg.rewind(); while (true ) { byte [] log = lg.next(); if (log == null ) break ; if (isInsertLog(log)) { InsertLogInfo li = parseInsertLog(log); long xid = li.xid; if (!tm.isActive(xid)) { doInsertLog(pc, log, REDO); } } else { UpdateLogInfo xi = parseUpdateLog(log); long xid = xi.xid; if (!tm.isActive(xid)) { doUpdateLog(pc, log, REDO); } } } }
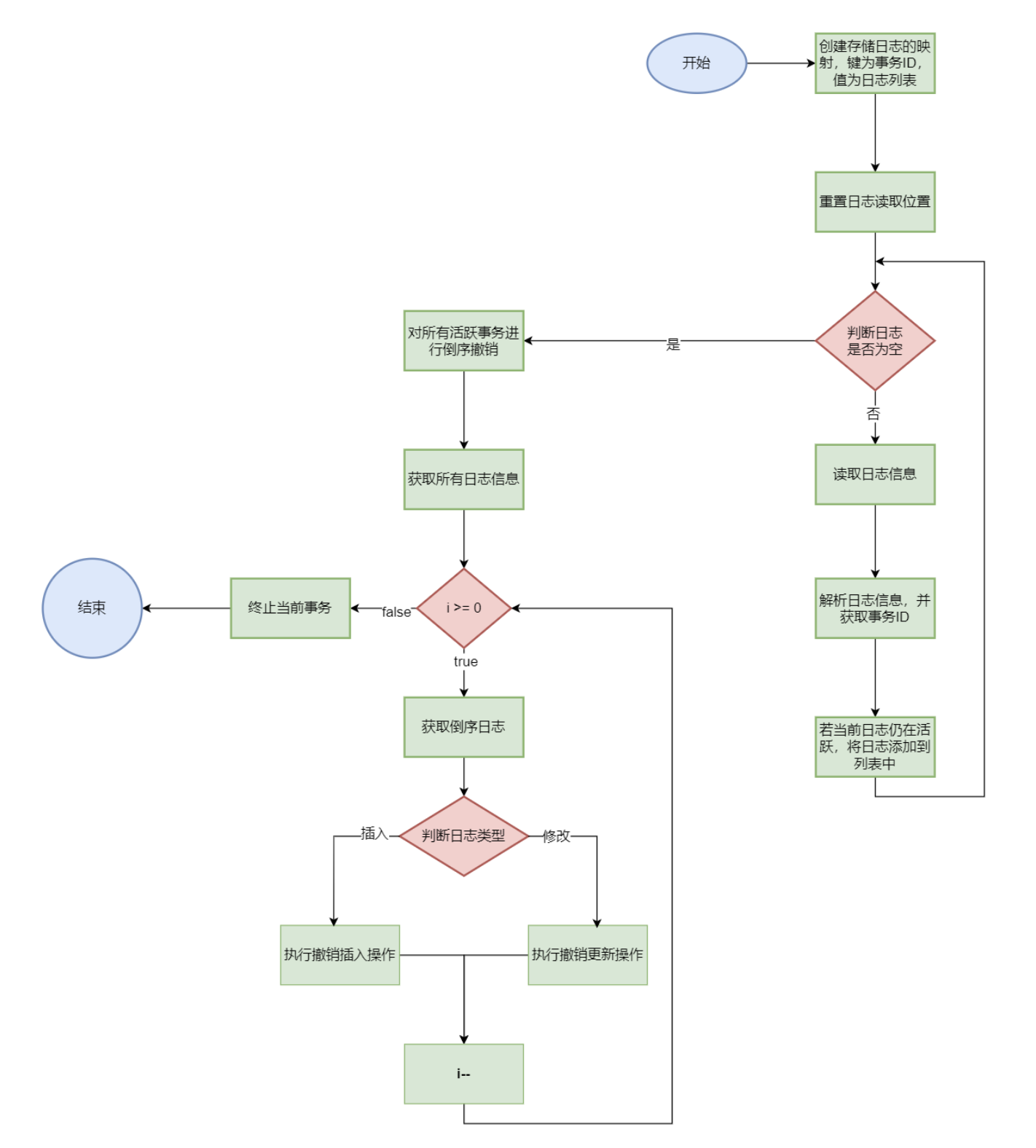
撤销所有未完成的事务 undolog
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 private static void undoTranscations (TransactionManager tm, Logger lg, PageCache pc) { Map<Long, List<byte []>> logCache = new HashMap <>(); lg.rewind(); while (true ) { byte [] log = lg.next(); if (log == null ) break ; if (isInsertLog(log)) { InsertLogInfo li = parseInsertLog(log); long xid = li.xid; if (tm.isActive(xid)) { if (!logCache.containsKey(xid)) { logCache.put(xid, new ArrayList <>()); } logCache.get(xid).add(log); } } else { UpdateLogInfo xi = parseUpdateLog(log); long xid = xi.xid; if (tm.isActive(xid)) { if (!logCache.containsKey(xid)) { logCache.put(xid, new ArrayList <>()); } logCache.get(xid).add(log); } } } for (Entry<Long, List<byte []>> entry : logCache.entrySet()) { List<byte []> logs = entry.getValue(); for (int i = logs.size() - 1 ; i >= 0 ; i--) { byte [] log = logs.get(i); if (isInsertLog(log)) { doInsertLog(pc, log, UNDO); } else { doUpdateLog(pc, log, UNDO); } } tm.abort(entry.getKey()); } }
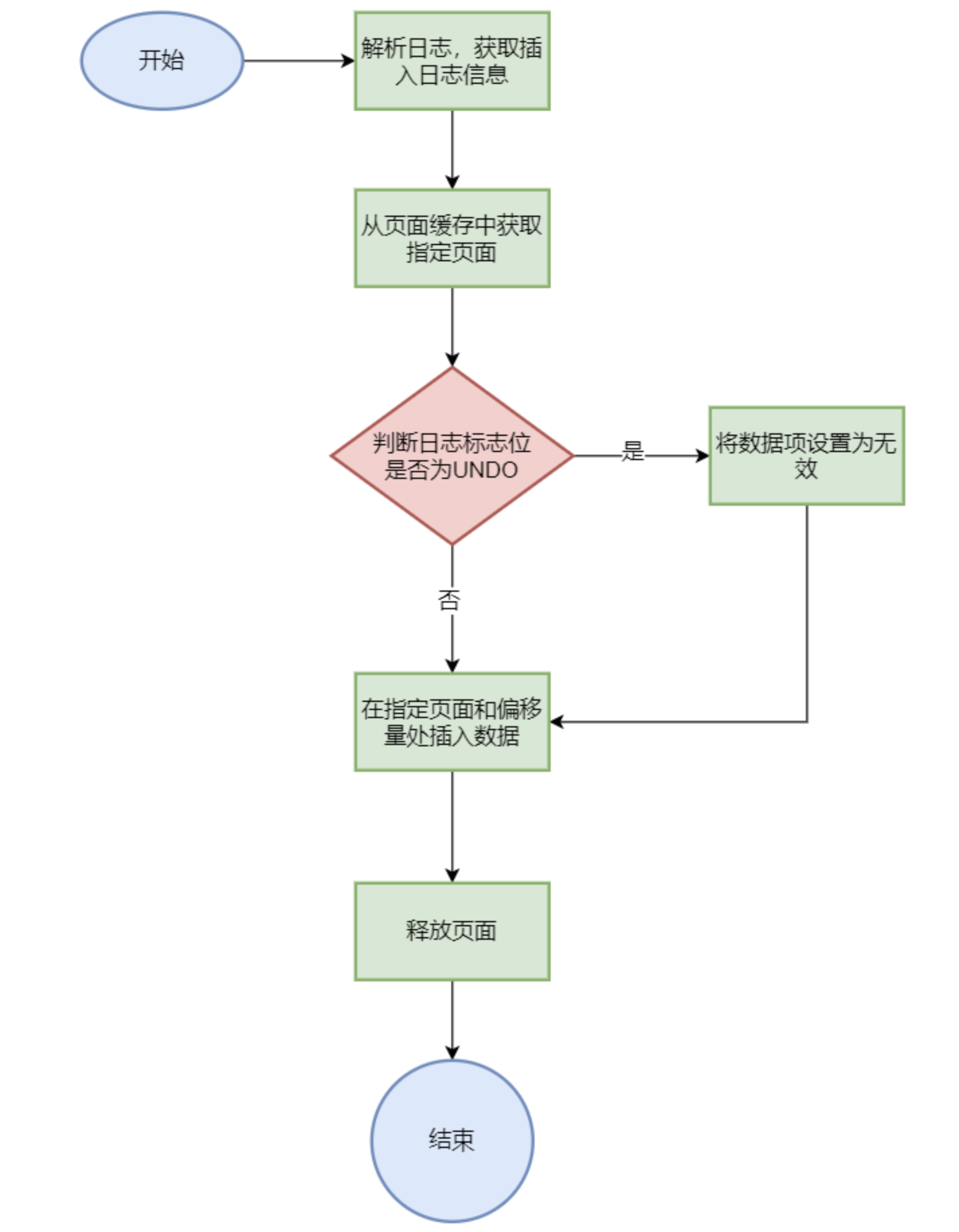
doInsertLog()以上两种事务的insert操作都是通过此方法完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private static void doInsertLog (PageCache pc, byte [] log, int flag) { InsertLogInfo li = parseInsertLog(log); Page pg = null ; try { pg = pc.getPage(li.pgno); } catch (Exception e) { Panic.panic(e); } try { if (flag == UNDO) { DataItem.setDataItemRawInvalid(li.raw); } PageX.recoverInsert(pg, li.raw, li.offset); } finally { pg.release(); } }
doUpdateLog()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private static void doUpdateLog (PageCache pc, byte [] log, int flag) { int pgno; short offset; byte [] raw; if (flag == REDO) { UpdateLogInfo xi = parseUpdateLog(log); pgno = xi.pgno; offset = xi.offset; raw = xi.newRaw; } else { UpdateLogInfo xi = parseUpdateLog(log); pgno = xi.pgno; offset = xi.offset; raw = xi.oldRaw; } Page pg = null ; try { pg = pc.getPage(pgno); } catch (Exception e) { Panic.panic(e); } try { PageX.recoverUpdate(pg, raw, offset); } finally { pg.release(); } }
页面索引 基本介绍 一定数量 的区间(这里是40个区间),并且在数据库启动时,会遍历所有页面,将每个页面的空闲空间信息分配到这些区间中。当需要进行插入操作时,插入操作首先会将所需的空间大小向上取整 ,然后映射到某一个区间,随后可以直接从该区间中选择任何一页,以满足插入需求。**PageIndex** 的实现使用了一个数组,数组的每个元素都是一个列表,用于存储具有相同空闲空间大小的页面信息。**PageIndex** 中获取页面的过程非常简单,只需要根据所需的空间大小计算出区间号,然后直接从对应的列表中取出一个页面即可。
注:以上内容来自原文跟GPT
PageIndex 1 2 3 4 5 6 7 8 9 public class PageIndex { private final List<PageInfo>[] lists; private static final int INTERVALS_NO = 40 ; private static final int THRESHOLD = PageCache.PAGE_SIZE / INTERVALS_NO; private Lock lock; }
select(int spaceSize)根据空闲空间的大小计算所处的编号位置,从PageIndex中获取页面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public PageInfo select (int spaceSize) { lock.lock(); try { int number = spaceSize / THRESHOLD; if (number < INTERVALS_NO) number++; while (number <= INTERVALS_NO) { if (lists[number].size() == 0 ) { number++; continue ; } return lists[number].remove(0 ); } return null ; } finally { lock.unlock(); } }
add()因为同一个页面是不允许并发写的,在上层模块使用完这个页面之后,需要重新将其插入到PaegIndex;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void add (int pgno, int freeSpace) { lock.lock(); try { int number = freeSpace / THRESHOLD; lists[number].add(new PageInfo (pgno, freeSpace)); } finally { lock.unlock(); } }
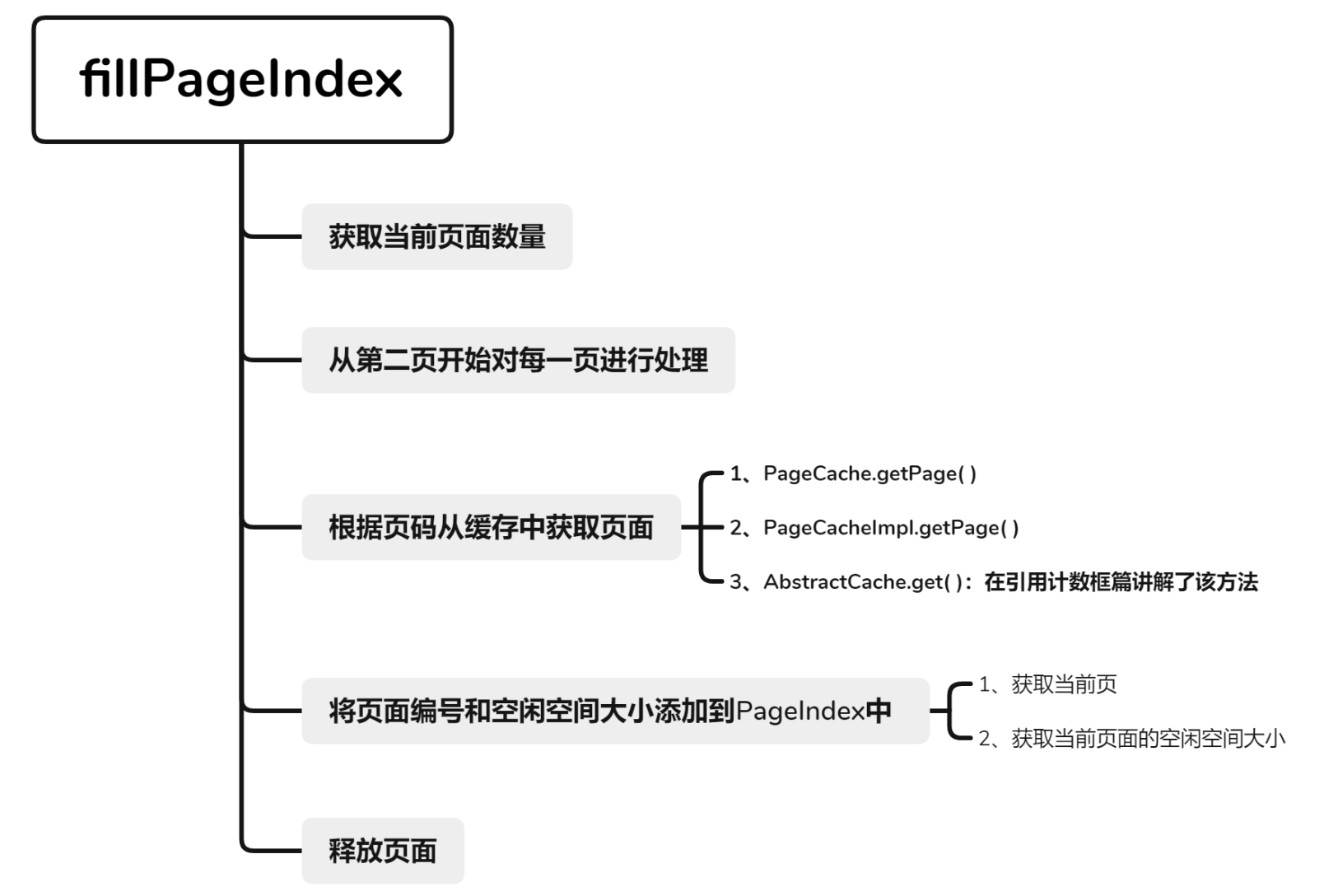
fillPageIndex() DataManager 被创建时,需要获取所有页面并填充 PageIndex:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void fillPageIndex () { int pageNumber = pc.getPageNumber(); for (int i = 2 ; i <= pageNumber; i++) { Page pg = null ; try { pg = pc.getPage(i); } catch (Exception e) { Panic.panic(e); } pIndex.add(pg.getPageNumber(), PageX.getFreeSpace(pg)); pg.release(); } }
DataItem 基本介绍
DataItem 是一个数据抽象层,它提供了一种在上层模块和底层数据存储之间进行交互的接口。其功能和作用主要包括:
数据存储和访问 :DataItem 存储了数据的具体内容,以及一些相关的元数据信息,如数据的大小、有效标志等。上层模块可以通过 DataItem 对象获取到其中的数据内容,以进行读取、修改或删除等操作。数据修改和事务管理 :DataItem 提供了一些方法来支持数据的修改操作,并在修改操作前后执行一系列的流程,如保存原始数据、落日志等。这些流程保证了数据修改的原子性和一致性,同时支持事务管理,确保了数据的安全性。数据共享和内存管理 :DataItem 的数据内容通过 SubArray 对象返回给上层模块,这使得上层模块可以直接访问数据内容而无需进行拷贝。这种数据共享的方式提高了数据的访问效率,同时减少了内存的开销。缓存管理 :DataItem 对象由底层的 DataManager 缓存管理,通过调用 release() 方法可以释放缓存中的 DataItem 对象,以便回收内存资源,提高系统的性能和效率。
DataItem 提供了一种高层次的数据抽象,隐藏了底层数据存储的细节,为上层模块提供了方便的数据访问和管理接口,同时保证了数据的安全性和一致性。
具体实现
DataItem 中保存的数据,结构如下:
1 [ValidFlag] [DataSize] [Data]
其中 **ValidFlag** 占用 1 字节,标识了该 **DataItem** 是否有效。删除一个 **DataItem**,只需要简单地将其有效位设置为 0。**DataSize** 占用 2 字节,标识了后面 **Data** 的长度。
1 2 3 4 5 6 7 public class DataItemImpl implements DataItem { private SubArray raw; private byte [] oldRaw; private DataManagerImpl dm; private long uid; private Page pg; }
data()返回数据项中的数据部分,返回的是原始数据的引用,而不是数据的拷贝
1 2 3 4 5 @Override public SubArray data () { return new SubArray (raw.raw, raw.start+OF_DATA, raw.end); }
before()在修改数据项之前调用,用于锁定数据项并保存原始数据
1 2 3 4 5 6 7 @Override public void before () { wLock.lock(); pg.setDirty(true ); System.arraycopy(raw.raw, raw.start, oldRaw, 0 , oldRaw.length); }
unbefore()在需要撤销修改时调用,用于恢复原始数据并解锁数据项
1 2 3 4 5 @Override public void unBefore () { System.arraycopy(oldRaw, 0 , raw.raw, raw.start, oldRaw.length); wLock.unlock(); }
after()在修改完成之后调用,用于记录日志并解锁数据项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Override public void after (long xid) { dm.logDataItem(xid, this ); wLock.unlock(); } public static byte [] updateLog(long xid, DataItem di) { byte [] logType = {LOG_TYPE_UPDATE}; byte [] xidRaw = Parser.long2Byte(xid); byte [] uidRaw = Parser.long2Byte(di.getUid()); byte [] oldRaw = di.getOldRaw(); SubArray raw = di.getRaw(); byte [] newRaw = Arrays.copyOfRange(raw.raw, raw.start, raw.end); return Bytes.concat(logType, xidRaw, uidRaw, oldRaw, newRaw); }
release()在使用完 **DataItem**后,需要调用 release() 释放调 DataItem的缓存
1 2 3 4 @Override public void release () { dm.releaseDataItem(this ); }
DM的实现 基本介绍
DataManager(DM)是数据库管理系统中的一层,主要负责底层数据的管理和操作。其功能和作用包括:
数据缓存和管理 :DataManager 实现了对 DataItem 对象的缓存管理,通过缓存管理,可以提高数据的访问效率,并减少对底层存储的频繁访问,从而提高系统的性能。数据访问和操作 :DataManager 提供了读取、插入和修改等数据操作方法,上层模块可以通过这些方法对数据库中的数据进行操作和管理。事务管理 :DataManager 支持事务的管理,通过事务管理,可以保证对数据的修改是原子性的,并且在事务提交或回滚时能够保持数据的一致性和完整性。日志记录和恢复 :DataManager 在数据修改操作前后会执行一系列的流程,包括日志记录和数据恢复等操作,以确保数据的安全性和可靠性,即使在系统崩溃或异常情况下也能够保证数据的完整性。页面索引管理 :DataManager 中实现了页面索引管理功能,通过页面索引可以快速定位到合适的空闲空间,从而提高数据插入的效率和性能。文件初始化和校验 :DataManager 在创建和打开数据库文件时,会进行文件的初始化和校验操作,以确保文件的正确性和完整性,同时在文件关闭时会执行相应的清理操作。资源管理和释放 :DataManager 在关闭时会执行资源的释放和清理操作,包括缓存和日志的关闭,以及页面的释放和页面索引的清理等。
DataManager 在数据库管理系统中扮演着重要的角色,负责底层数据的管理和操作,为上层模块提供了方便的数据访问和操作接口,同时通过事务管理和日志记录等功能保证了数据的安全性和可靠性。
注:以上内容来自GPT
具体实现 DataManager 是 DM 层直接对外提供方法的类,同时,也实现成 DataItem 对象的缓存。DataItem 存储的 **key**,是由页号和页内偏移组成的一个 8 字节无符号整数,页号和偏移各占 4 字节。
Uid生成以及解析
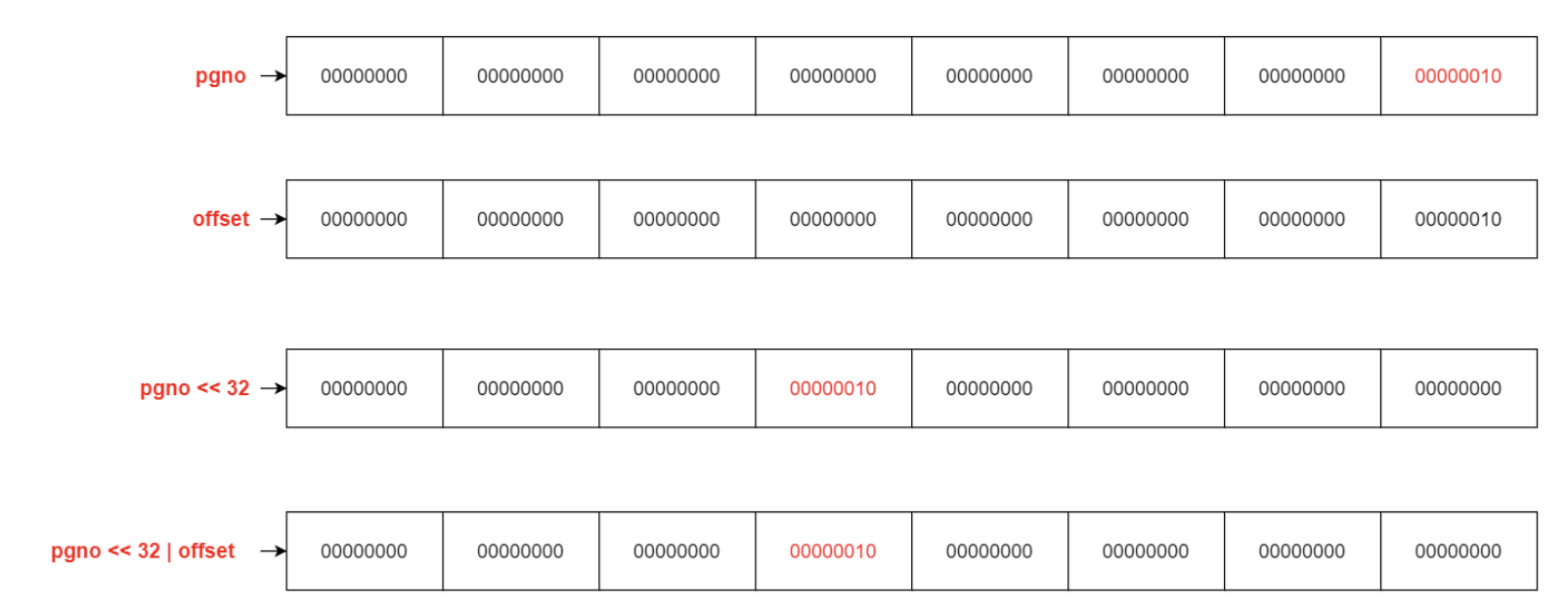
初始化:假设是从第二个页面开始的,并且偏移量为0pgno: 2; offset: 0;
先通过页面编号以及偏移量生成唯一标识 uid
1 2 3 4 5 6 7 public class Types { public static long addressToUid (int pgno, short offset) { long u0 = (long )pgno; long u1 = (long )offset; return u0 << 32 | u1; } }
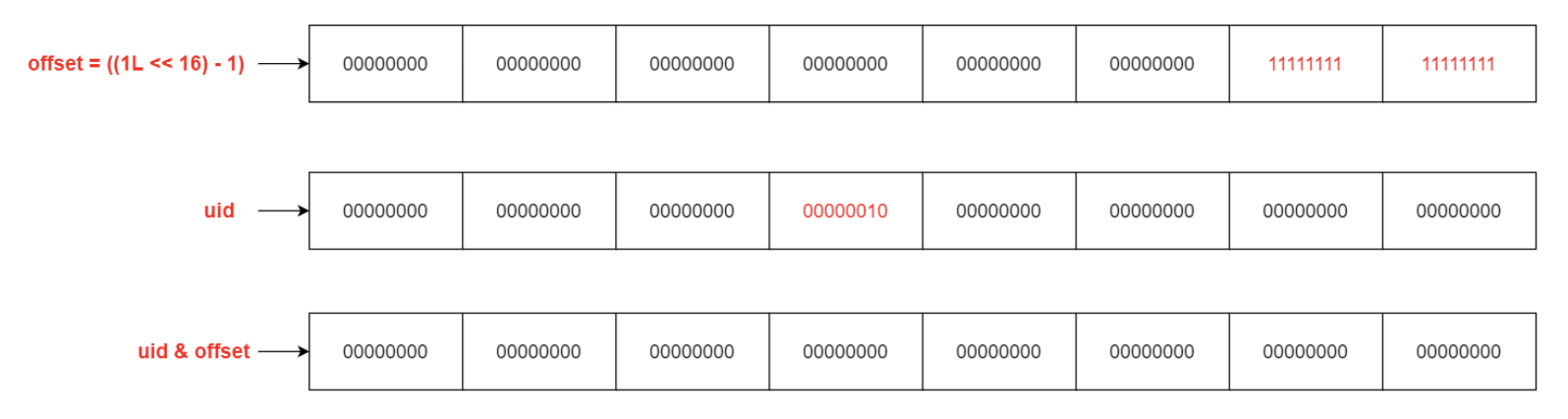
从 uid 中提取出偏移量(offset )
1 2 3 short offset = (short ) (uid & ((1L << 16 ) - 1 ));
将 uid 右移32位,再获取页面编号
1 2 3 4 5 uid >>>= 32 ; int pgno = (int ) (uid & ((1L << 32 ) - 1 ));
getForCache()也是继承自AbstractCache,只需要从 key 中解析出页号,从 pageCache 中获取到页面,再根据偏移,解析出 DataItem 即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override protected DataItem getForCache (long uid) throws Exception { short offset = (short ) (uid & ((1L << 16 ) - 1 )); uid >>>= 32 ; int pgno = (int ) (uid & ((1L << 32 ) - 1 )); Page pg = pc.getPage(pgno); return DataItem.parseDataItem(pg, offset, this ); }
releaseForCache()DataItem 缓存释放,需要将 DataItem 写回数据源,由于对文件的读写是以页为单位进行的,只需要将 DataItem 所在的页 release 即可:
1 2 3 4 @Override protected void releaseForCache (DataItem di) { di.page().release(); }
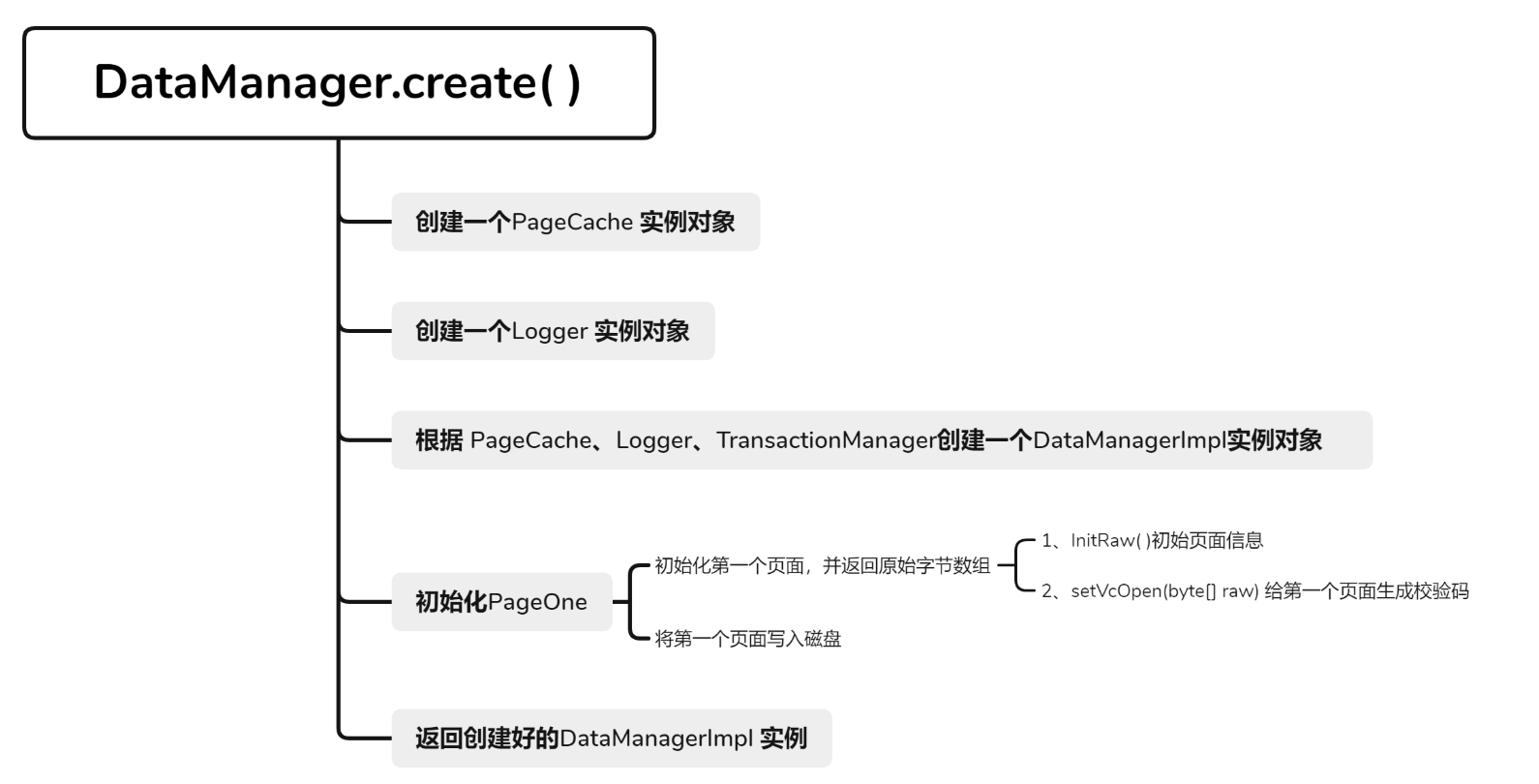
DataManager初始化 对于**DataManager**文件的创建有两种流程,一种是从已有文件创建**DataManager**, 另外一种是从空文件创建**DataManager**。 对于两者的不同主要在于第一页的初始化和校验问题:
从空文件创建首先需要对第一页进行初始化
而从已有文件创建,则需要对第一页进行校验,来判断是否需要执行恢复流程,并重新对第一页生成随机字节
从空文件创建create()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static DataManager create (String path, long mem, TransactionManager tm) { PageCache pc = PageCache.create(path, mem); Logger lg = Logger.create(path); DataManagerImpl dm = new DataManagerImpl (pc, lg, tm); dm.initPageOne(); return dm; }
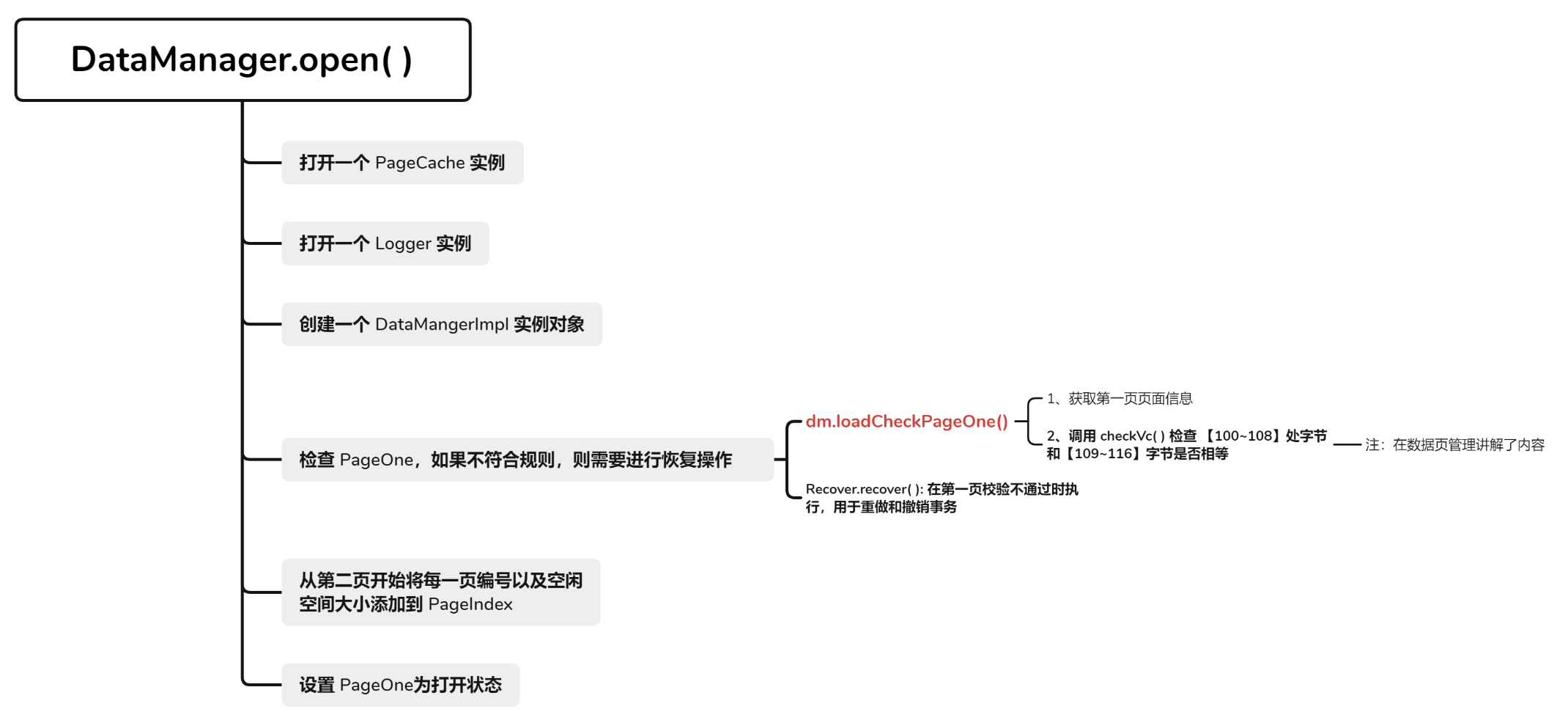
从已有文件创建open()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static DataManager open (String path, long mem, TransactionManager tm) { PageCache pc = PageCache.open(path, mem); Logger lg = Logger.open(path); DataManagerImpl dm = new DataManagerImpl (pc, lg, tm); if (!dm.loadCheckPageOne()) { Recover.recover(tm, lg, pc); } dm.fillPageIndex(); PageOne.setVcOpen(dm.pageOne); dm.pc.flushPage(dm.pageOne); return dm; }
DataManager 提供的三个功能 **DM**层主要提供了三个功能供上层使用,分别是读、插入和修改。由于修改是通过读出的 **DataItem** 实现的,也就是说 **DataManager** 只需要 **read()** 和 **insert()** 方法;
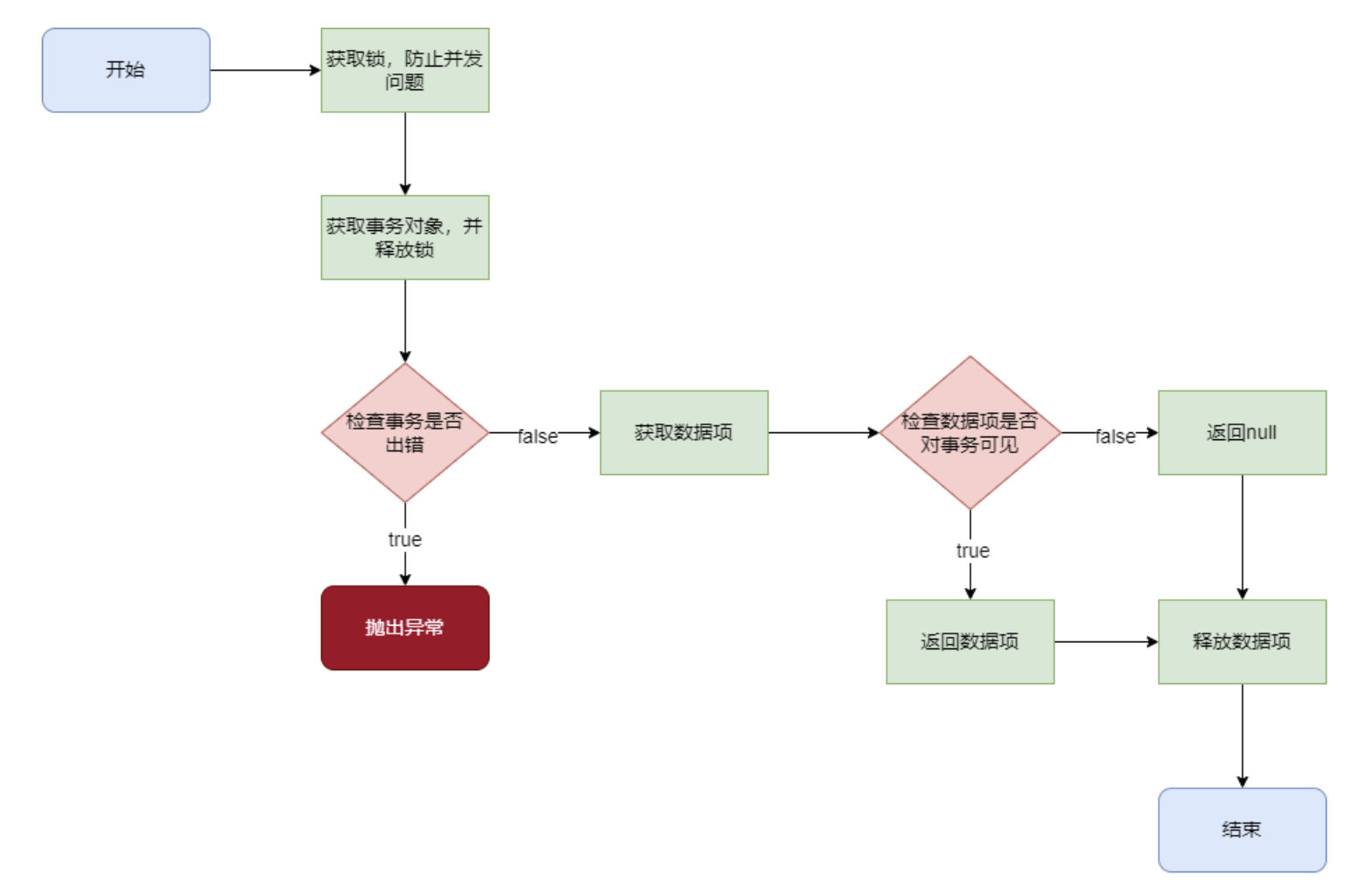
read()**read()**** **是根据 UID 从缓存中获取的 **DataItem**,并校验有效位;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Override public DataItem read (long uid) throws Exception { DataItemImpl di = (DataItemImpl) super .get(uid); if (!di.isValid()) { di.release(); return null ; } return di; } @Override protected DataItem getForCache (long uid) throws Exception { short offset = (short ) (uid & ((1L << 16 ) - 1 )); uid >>>= 32 ; int pgno = (int ) (uid & ((1L << 32 ) - 1 )); Page pg = pc.getPage(pgno); return DataItem.parseDataItem(pg, offset, this ); }
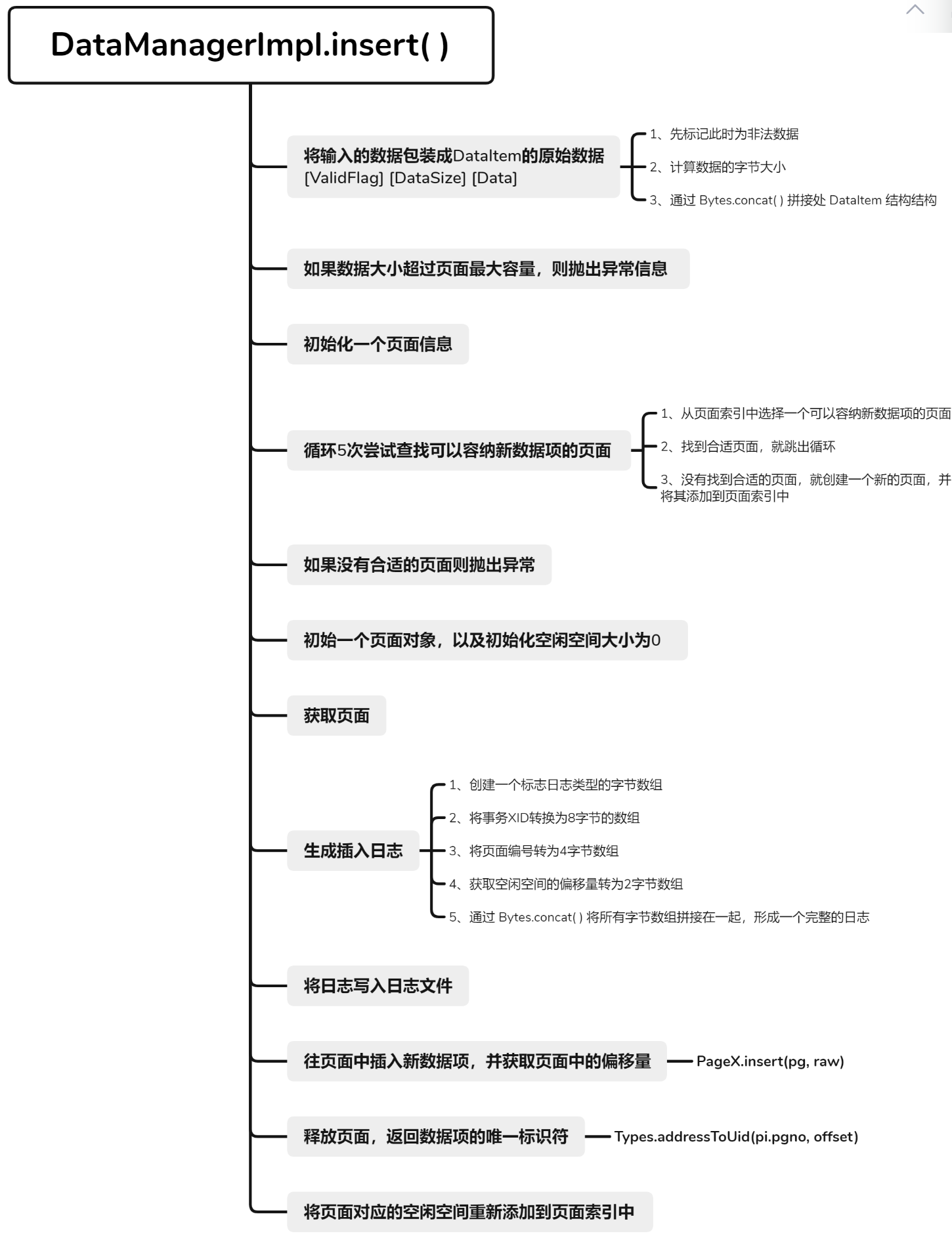
insert()在 **pageIndex** 中获取一个足以存储插入内容的页面的页号,获取页面后,首先需要写入插入日志,接着才可以通过 **pageX** 插入数据,并返回插入位置的偏移。最后需要将页面信息重新插入 **pageIndex**。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 @Override public long insert (long xid, byte [] data) throws Exception { byte [] raw = DataItem.wrapDataItemRaw(data); if (raw.length > PageX.MAX_FREE_SPACE) { throw Error.DataTooLargeException; } PageInfo pi = null ; for (int i = 0 ; i < 5 ; i++) { pi = pIndex.select(raw.length); if (pi != null ) { break ; } else { int newPgno = pc.newPage(PageX.initRaw()); pIndex.add(newPgno, PageX.MAX_FREE_SPACE); } } if (pi == null ) { throw Error.DatabaseBusyException; } Page pg = null ; int freeSpace = 0 ; try { pg = pc.getPage(pi.pgno); byte [] log = Recover.insertLog(xid, pg, raw); logger.log(log); short offset = PageX.insert(pg, raw); pg.release(); return Types.addressToUid(pi.pgno, offset); } finally { if (pg != null ) { pIndex.add(pi.pgno, PageX.getFreeSpace(pg)); } else { pIndex.add(pi.pgno, freeSpace); } } } public static byte [] wrapDataItemRaw(byte [] raw) { byte [] valid = new byte [1 ]; byte [] size = Parser.short2Byte((short )raw.length); return Bytes.concat(valid, size, raw); } public PageInfo select (int spaceSize) { lock.lock(); try { int number = spaceSize / THRESHOLD; if (number < INTERVALS_NO) number++; while (number <= INTERVALS_NO) { if (lists[number].size() == 0 ) { number++; continue ; } return lists[number].remove(0 ); } return null ; } finally { lock.unlock(); } } public static byte [] insertLog(long xid, Page pg, byte [] raw) { byte [] logTypeRaw = {LOG_TYPE_INSERT}; byte [] xidRaw = Parser.long2Byte(xid); byte [] pgnoRaw = Parser.int2Byte(pg.getPageNumber()); byte [] offsetRaw = Parser.short2Byte(PageX.getFSO(pg)); return Bytes.concat(logTypeRaw, xidRaw, pgnoRaw, offsetRaw, raw); } public static short insert (Page pg, byte [] raw) { pg.setDirty(true ); short offset = getFSO(pg.getData()); System.arraycopy(raw, 0 , pg.getData(), offset, raw.length); setFSO(pg.getData(), (short ) (offset + raw.length)); return offset; }
close()DataManager 正常关闭时,需要执行缓存和日志的关闭流程,还需要设置第一页的字节校验:
1 2 3 4 5 6 7 8 9 @Override public void close () { super .close(); logger.close(); PageOne.setVcClose(pageOne); pageOne.release(); pc.close(); }
Version Manager (VM) 版本管理器 2PL 与 MVCC 冲突与 2PL
1 2 3 这两个操作是由不同的事务执行的 这两个操作操作的是同一个数据项 这两个操作至少有一个是更新操作
那么这样,对同一个数据操作的冲突,其实就只有下面这两种情况:
1 2 两个不同事务的 U 操作冲突 两个不同事务的 U、R 操作冲突
那么冲突或者不冲突,意义何在? 互不冲突 的操作的顺序,不会对最终的结果造成影响,而交换两个冲突 操作的顺序,则是会有影响的。
现在我们先抛开冲突不谈,记得在第四章举的例子吗,在并发情况下,两个事务同时操作 x。假设 x 的初值是 0:
1 2 3 4 5 6 7 8 T1 begin T2 begin R1(x) // T1 读到 0 R2(x) // T2 读到 0 U1(0+1) // T1 尝试把 x+1 U2(0+1) // T2 尝试把 x+1 T1 commit T2 commit
最后 x 的结果是 1,这个结果显然与期望的不符。
VM 的一个很重要的职责,就是实现了调度序列的可串行化。MYDB 采用两段锁协议(2PL)来实现。当采用 2PL 时,如果某个事务 i 已经对 x 加锁,且另一个事务 j 也想操作 x,但是这个操作与事务 i 之前的操作相互冲突的话,事务 j 就会被阻塞。譬如,T1 已经因为 U1(x) 锁定了 x,那么 T2 对 x 的读或者写操作都会被阻塞,T2 必须等待 T1 释放掉对 x 的锁。
由此来看,2PL 确实保证了调度序列的可串行话,但是不可避免地导致了事务间的相互阻塞,甚至可能导致死锁。MYDB 为了提高事务处理的效率,降低阻塞概率,实现了 MVCC。
MVCC
在介绍 MVCC 之前,首先明确记录和版本的概念。
DM 层向上层提供了数据项(Data Item)的概念,VM 通过管理所有的数据项,向上层提供了记录(Entry)的概念。上层模块通过 VM 操作数据的最小单位,就是记录。VM 则在其内部,为每个记录,维护了多个版本(Version)。每当上层模块对某个记录进行修改时,VM 就会为这个记录创建一个新的版本。
MYDB 通过 MVCC,降低了事务的阻塞概率。譬如,T1 想要更新记录 X 的值,于是 T1 需要首先获取 X 的锁,接着更新,也就是创建了一个新的 X 的版本,假设为 x3。假设 T1 还没有释放 X 的锁时,T2 想要读取 X 的值,这时候就不会阻塞,MYDB 会返回一个较老版本的 X,例如 x2。这样最后执行的结果,就等价于,T2 先执行,T1 后执行,调度序列依然是可串行化的。如果 X 没有一个更老的版本,那只能等待 T1 释放锁了。所以只是降低了概率。
还记得我们在恢复策略章节中,为了保证数据的可恢复,VM 层传递到 DM 的操作序列需要满足以下两个规则:
1 2 规定 1:正在进行的事务,不会读取其他任何未提交的事务产生的数据。 规定 2:正在进行的事务,不会修改其他任何未提交的事务修改或产生的数据。
由于 2PL 和 MVCC,我们可以看到,这两个条件都被很轻易地满足了。
前言
tips:
如何实现版本记录? Entry格式数据
[XMIN] [XMAX] [DATA]
XMIN 是创建该条记录(版本)的事务编号**XMAX **则是删除该条记录(版本)的事务编号
**DATA **就是这条记录持有的数据
Entry结构 对于一条记录来说,MYDB 使用 Entry 类维护了其结构。虽然理论上,MVCC 实现了多版本,但是在实现中,VM 并没有提供 Update 操作,对于字段的更新操作由后面的表和字段管理(TBM)实现。所以在 VM 的实现中,一条记录只有一个版本。 由于一条记录存储在一条 Data Item 中,所以 Entry 中保存一个 DataItem 的引用即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Entry { private static final int OF_XMIN = 0 ; private static final int OF_XMAX = OF_XMIN+8 ; private static final int OF_DATA = OF_XMAX+8 ; private long uid; private DataItem dataItem; private VersionManager vm; public static Entry loadEntry (VersionManager vm, long uid) throws Exception { DataItem di = ((VersionManagerImpl)vm).dm.read(uid); return newEntry(vm, di, uid); } public void remove () { dataItem.release(); } }
日志格式操作 wrapEntryRaw()1 2 3 4 5 6 7 8 9 10 11 public static byte [] wrapEntryRaw(long xid, byte [] data) { byte [] xmin = Parser.long2Byte(xid); byte [] xmax = new byte [8 ]; return Bytes.concat(xmin, xmax, data); }
data()获取记录中持有的数据,也就需要按照上面这个结构来解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public byte [] data() { dataItem.rLock(); try { SubArray sa = dataItem.data(); byte [] data = new byte [sa.end - sa.start - OF_DATA]; System.arraycopy(sa.raw, sa.start+OF_DATA, data, 0 , data.length); return data; } finally { dataItem.rUnLock(); } }
setXmax()当需要对数据进行修改时,就需要设置 xmax的值;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void setXmax (long xid) { dataItem.before(); try { SubArray sa = dataItem.data(); System.arraycopy(Parser.long2Byte(xid), 0 , sa.raw, sa.start+OF_XMAX, 8 ); } finally { dataItem.after(xid); } }
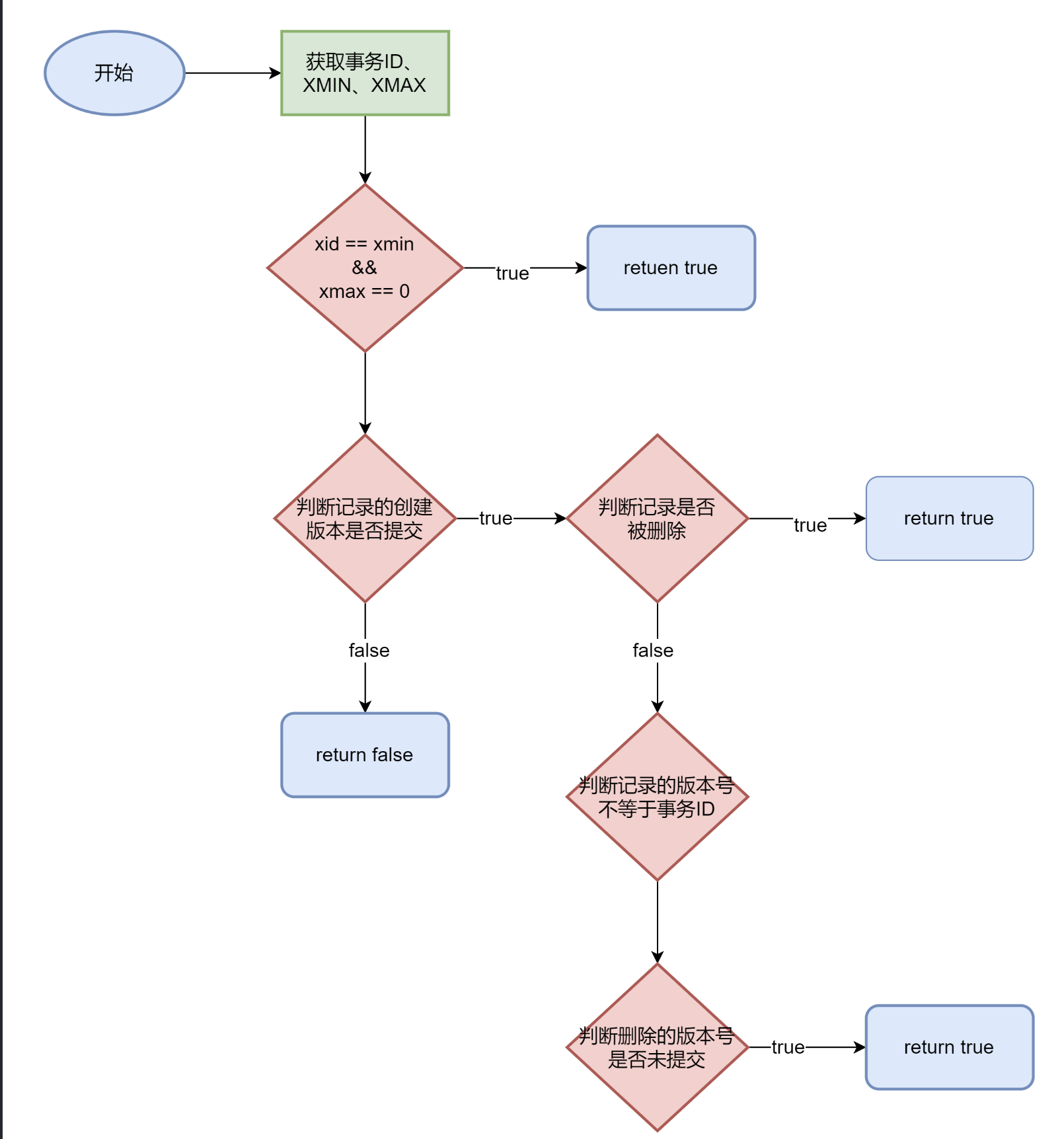
事物的隔离级别 读提交 在数据库中,“读提交”(Read Committed)是一种事务隔离级别,表示在读取数据时,事务只能读取已经提交的事务产生的数据。这意味着当一个事务正在读取数据时,如果其他事务正在修改相同的数据,它只能读取已经被提交的修改,而无法读取尚未提交的修改。XMIN 和XMAX 。
XMIN 表示创建该版本的事务编号。当一个事务创建了一个新的版本时,XMIN会记录该事务的编号。XMAX 表示删除该版本的事务编号。当一个版本被删除时,或者有新版本出现时,XMAX会记录删除该版本的事务编号。
读提交的事务可见性逻辑
如果版本的XMIN等于当前事务的事务编号,并且XMAX为空(表示尚未被删除),则该版本对当前事务可见。
或者,如果版本的XMIN对应的事务已经提交,并且XMAX为空(尚未被删除),或者XMAX不是当前事务的事务编号,并且XMAX对应的事务也已经提交,则该版本对当前事务可见。
在读提交隔离级别下,事务只能看到已经提交的版本,而不能看到尚未提交的版本或被尚未提交的事务删除的版本。这样可以确保读取的数据是稳定和一致的,同时避免了读取到不一致或未提交的数据的可能性。
1 2 3 4 5 6 7 8 (XMIN == Ti and // 由Ti创建且 XMAX == NULL // 还未被删除 ) or // 或 (XMIN is commited and // 由一个已提交的事务创建且 (XMAX == NULL or // 尚未删除或 (XMAX != Ti and XMAX is not commited) // 由一个未提交的事务删除 ))
readCommited()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private static boolean readCommitted (TransactionManager tm, Transaction t, Entry e) { long xid = t.xid; long xmin = e.getXmin(); long xmax = e.getXmax(); if (xmin == xid && xmax == 0 ) return true ; if (tm.isCommitted(xmin)) { if (xmax == 0 ) return true ; if (xmax != xid) { if (!tm.isCommitted(xmax)) { return true ; } } } return false ; }
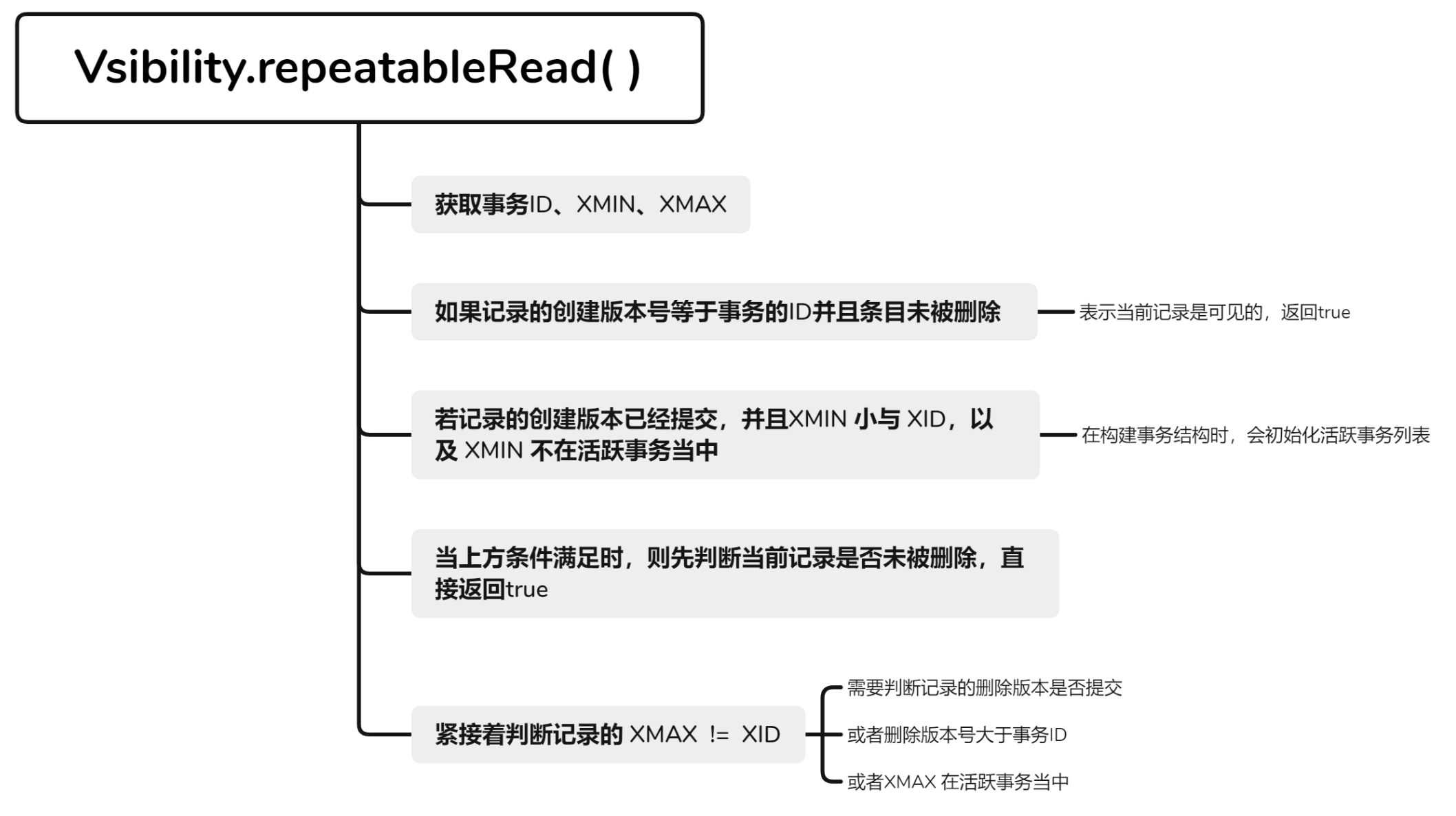
可重复读 在数据库中,可重复读(Repeatable Read) 是一种事务隔离级别,它解决了读提交隔离级别下的不可重复读问题。在可重复读隔离级别下,一个事务执行期间多次读取同一数据项,可以保证读取到的结果是一致的,不会因为其他事务的并发操作而导致数据的不一致性。不可重复 读问题指的是,在读提交隔离级别下,一个事务在执行过程中多次读取同一数据项,但由于其他事务的并发修改操作,导致每次读取到的数据值不同,出现了不一致的情况。可重复读隔离级别通过更严格的规则来解决这个问题。事务只能读取它开始时已经提交的事务产生的数据版本 。这意味着,在事务开始时已经提交的所有事务所产生的数据对当前事务是可见的,而在事务开始后产生的其他事务所产生的数据对当前事务则是不可见的。这样可以确保事务在执行期间读取到的数据是一致的,不会受到其他事务的影响。
可重复读的事务可见性逻辑
如果版本的XMIN 等于当前事务的事务编号,并且XMAX 为空(表示尚未被删除),则该版本对当前事务可见。
或者,如果版本的XMIN 对应的事务已经提交,并且XMIN 小于当前事务的事务编号,并且XMIN 不在当前事务开始前活跃的事务集合SP(Ti)中,同时 XMAX 为空(尚未被删除),或者XMAX 不是当前事务的事务编号,并且XMAX 对应的事务已经提交,并且XMAX 大于当前事务的事务编号,或者XMAX在当前事务开始前活跃的事务集合SP(Ti)中,则该版本对当前事务可见。1 2 3 4 5 6 7 8 9 10 11 12 13 (XMIN == Ti and // 由Ti创建且 (XMAX == NULL or // 尚未被删除 )) or // 或 (XMIN is commited and // 由一个已提交的事务创建且 XMIN < XID and // 这个事务小于Ti且 XMIN is not in SP(Ti) and // 这个事务在Ti开始前提交且 (XMAX == NULL or // 尚未被删除或 (XMAX != Ti and // 由其他事务删除但是 (XMAX is not commited or // 这个事务尚未提交或 XMAX > Ti or // 这个事务在Ti开始之后才开始或 XMAX is in SP(Ti) // 这个事务在Ti开始前还未提交 ))))
事务结构 由于可重复读 事务的可见性逻辑,需要提供一个结构,用来抽象事务,以保存快照数据;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class Transaction { public long xid; public int level; public Map<Long, Boolean> snapshot; public Exception err; public boolean autoAborted; public static Transaction newTransaction (long xid, int level, Map<Long, Transaction> active) { Transaction t = new Transaction (); t.xid = xid; t.level = level; if (level != 0 ) { t.snapshot = new HashMap <>(); for (Long x : active.keySet()) { t.snapshot.put(x, true ); } } return t; } public boolean isInSnapshot (long xid) { if (xid == TransactionManagerImpl.SUPER_XID) { return false ; } return snapshot.containsKey(xid); } }
repeatableRead()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private static boolean repeatableRead (TransactionManager tm, Transaction t, Entry e) { long xid = t.xid; long xmin = e.getXmin(); long xmax = e.getXmax(); if (xmin == xid && xmax == 0 ) return true ; if (tm.isCommitted(xmin) && xmin < xid && !t.isInSnapshot(xmin)) { if (xmax == 0 ) return true ; if (xmax != xid) { if (!tm.isCommitted(xmax) || xmax > xid || t.isInSnapshot(xmax)) { return true ; } } } return false ; }
死锁检测 版本跳跃问题 版本跳跃问题是指在多版本并发控制(MVCC)中,一个事务要修改某个数据项时,可能会出现跳过中间版本直接修改最新版本的情况,从而产生逻辑上的错误。解决版本跳跃的关键在于检查最新版本的创建者对当前事务是否可见。如果当前事务要修改的数据已经被另一个事务修改并且对当前事务不可见,就要求当前事务回滚。具体来说,对于事务Ti要修改数据X的情况下,要检查如下两种情况:
如果另一个事务Tj的事务ID(XID)大于Ti的事务ID,则Tj在时间上晚于Ti开始,因此Ti应该回滚,避免版本跳跃。
如果Tj在Ti的快照集合(SP(Ti))中,则Tj在Ti开始之前已经提交,但Ti在开始之前并不能看到Tj的修改,因此也应该回滚。
版本跳跃的检查 因为读提交是允许版本跳跃的,可重复读是不允许的,所以只需要检查读提交即可
1 2 3 4 5 6 7 8 9 10 11 12 public static boolean isVersionSkip (TransactionManager tm, Transaction t, Entry e) { long xmax = e.getXmax(); if (t.level == 0 ) { return false ; } else { return tm.isCommitted(xmax) && (xmax > t.xid || t.isInSnapshot(xmax)); } }
LockTable 上文提到了在基于2PL(两段锁协议) 的并发控制中,当一个事务(例如Tj)想要获取某个数据项的锁时,如果该锁已经被其他事务(例如Ti)持有,则Tj会被阻塞,直到Ti释放了该锁。这种等待关系可以被抽象成有向边,比如Tj在等待Ti,可以表示为Tj → Ti。通过记录所有事务之间的等待关系,就可以构建一个有向图,即等待图(Wait-for graph)。在等待图中,如果存在环路,即存在一个事务的等待序列形成了一个闭环,那么就说明存在死锁。因此,检测死锁只需要查看等待图中是否存在环即可。
LockTable基本结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class LockTable { private Map<Long, List<Long>> x2u; private Map<Long, Long> u2x; private Map<Long, List<Long>> wait; private Map<Long, Lock> waitLock; private Map<Long, Long> waitU; private Lock lock; }
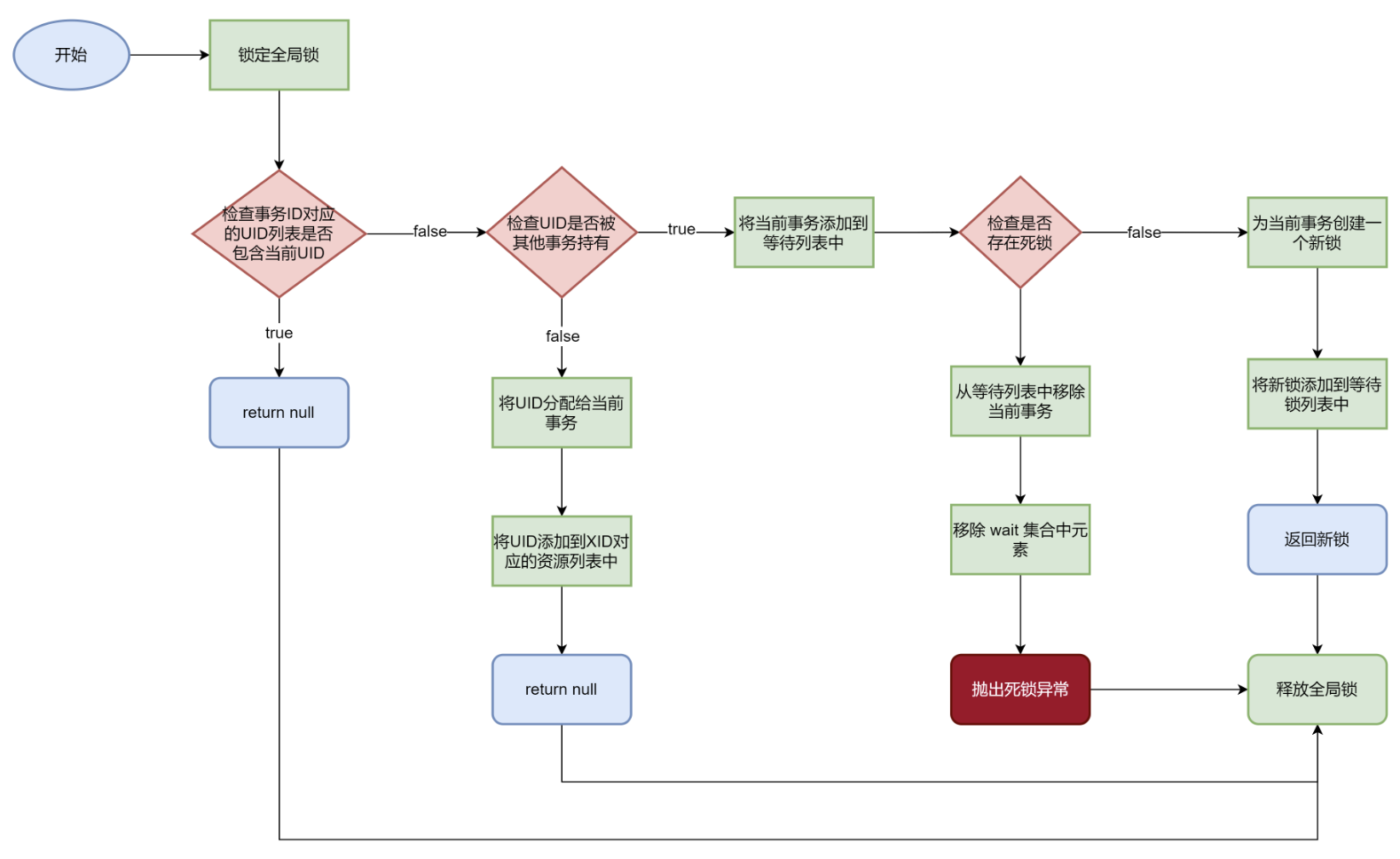
add()在每次出现等待的情况时,就尝试向图中增加一条边,并进行死锁检测。如果检测到死锁,就撤销这条边,不允许添加,并撤销该事务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public Lock add (long xid, long uid) throws Exception { lock.lock(); try { if (isInList(x2u, xid, uid)) { return null ; } if (!u2x.containsKey(uid)) { u2x.put(uid, xid); putIntoList(x2u, xid, uid); return null ; } waitU.put(xid, uid); putIntoList(wait, uid, xid); if (hasDeadLock()) { waitU.remove(xid); removeFromList(wait, uid, xid); throw Error.DeadlockException; } Lock l = new ReentrantLock (); l.lock(); waitLock.put(xid, l); return l; } finally { lock.unlock(); } }
hasDeadLock() and dfs()检查是否包含死锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 private boolean hasDeadLock () { xidStamp = new HashMap <>(); stamp = 1 ; for (long xid : x2u.keySet()) { Integer s = xidStamp.get(xid); if (s != null && s > 0 ) { continue ; } stamp++; if (dfs(xid)) { return true ; } } return false ; } private boolean dfs (long xid) { Integer stp = xidStamp.get(xid); if (stp != null && stp == stamp) { return true ; } if (stp != null && stp < stamp) { return false ; } xidStamp.put(xid, stamp); Long uid = waitU.get(xid); if (uid == null ) return false ; Long x = u2x.get(uid); assert x != null ; return dfs(x); }
死锁演示 前言
lockTable.add(1, 1); // 事务1请求资源1
lockTable.add(2, 2); // 事务2请求资源2
lockTable.add(3, 3); // 事务3请求资源3
lockTable.add(1, 2); // 事务1请求资源2
lockTable.add(2, 3); // 事务2请求资源3
lockTable.add(3, 1); // 事务3请求资源1
在这些数据添加完毕之后,事务1在等待事务2,事务2在等待事务3,事务3又在等待事务1,此时就触发了死锁!
当数据添加完毕之后,LockTable类中的MAP集合对着一下元素:
x2u
u2x
wait
waitU
dfs()演示过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 第一遍:xidStamp = null ,stamp=2 private boolean dfs (long xid) { Integer stp = xidStamp.get(xid); xidStamp.put(xid, stamp); Long uid = waitU.get(xid); Long x = u2x.get(uid); return dfs(x); } 第二遍:xidStamp = {1 =2 },stamp=2 private boolean dfs (long xid) { Integer stp = xidStamp.get(xid); xidStamp.put(xid, stamp); Long uid = waitU.get(xid); Long x = u2x.get(uid); return dfs(x); } 第三遍:xidStamp = {1 =2 ,2 =2 },stamp=2 private boolean dfs (long xid) { Integer stp = xidStamp.get(xid); xidStamp.put(xid, stamp); Long uid = waitU.get(xid); Long x = u2x.get(uid); return dfs(x); } 第四遍:xidStamp = {1 =2 ,2 =2 ,3 =2 },stamp=2 private boolean dfs (long xid) { Integer stp = xidStamp.get(xid); if (stp != null && stp == stamp) { return true ; } }
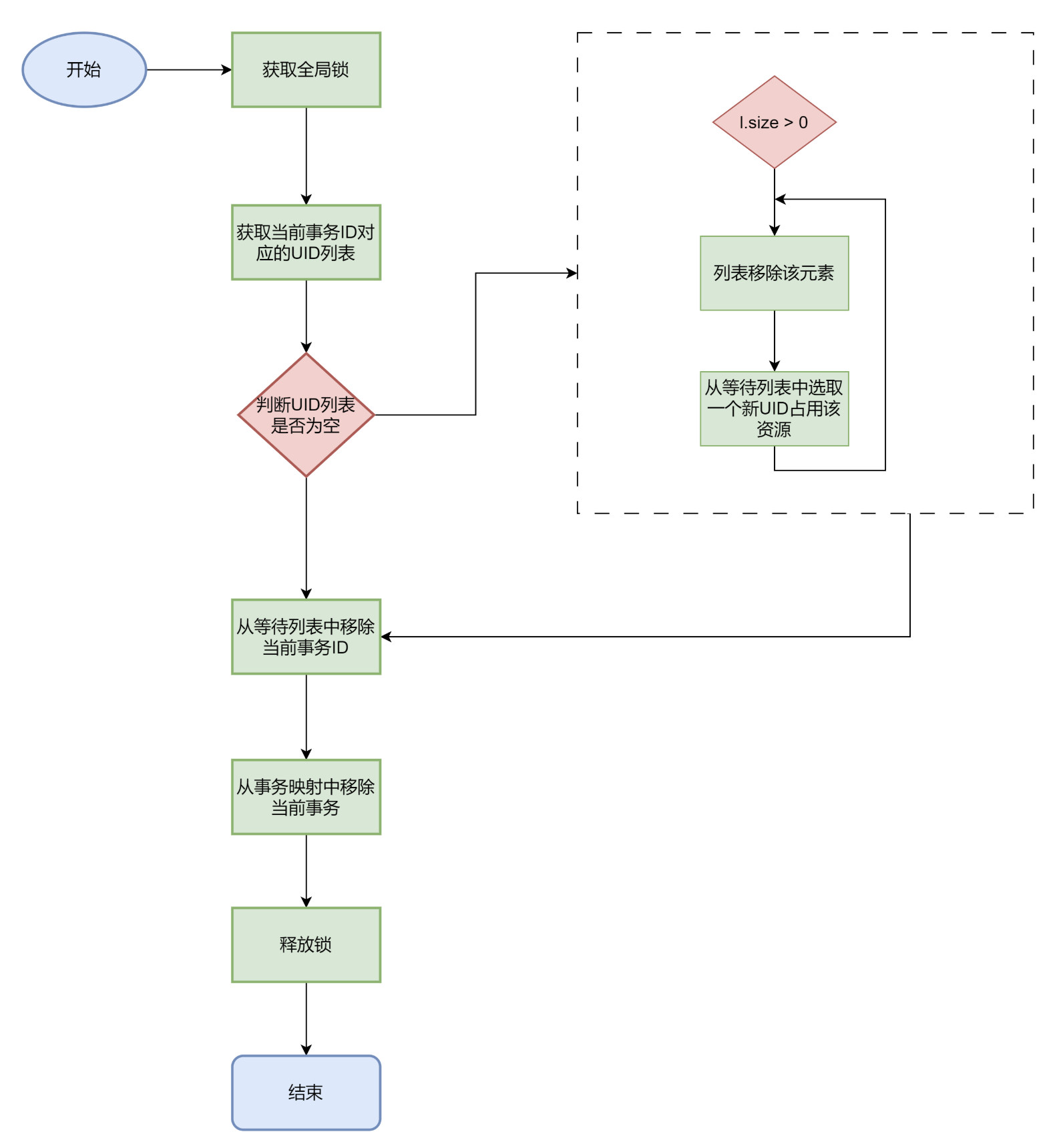
remove()当一个事务commit或者abort时,就会释放掉它自己持有的锁,并将自身从等待图中删除
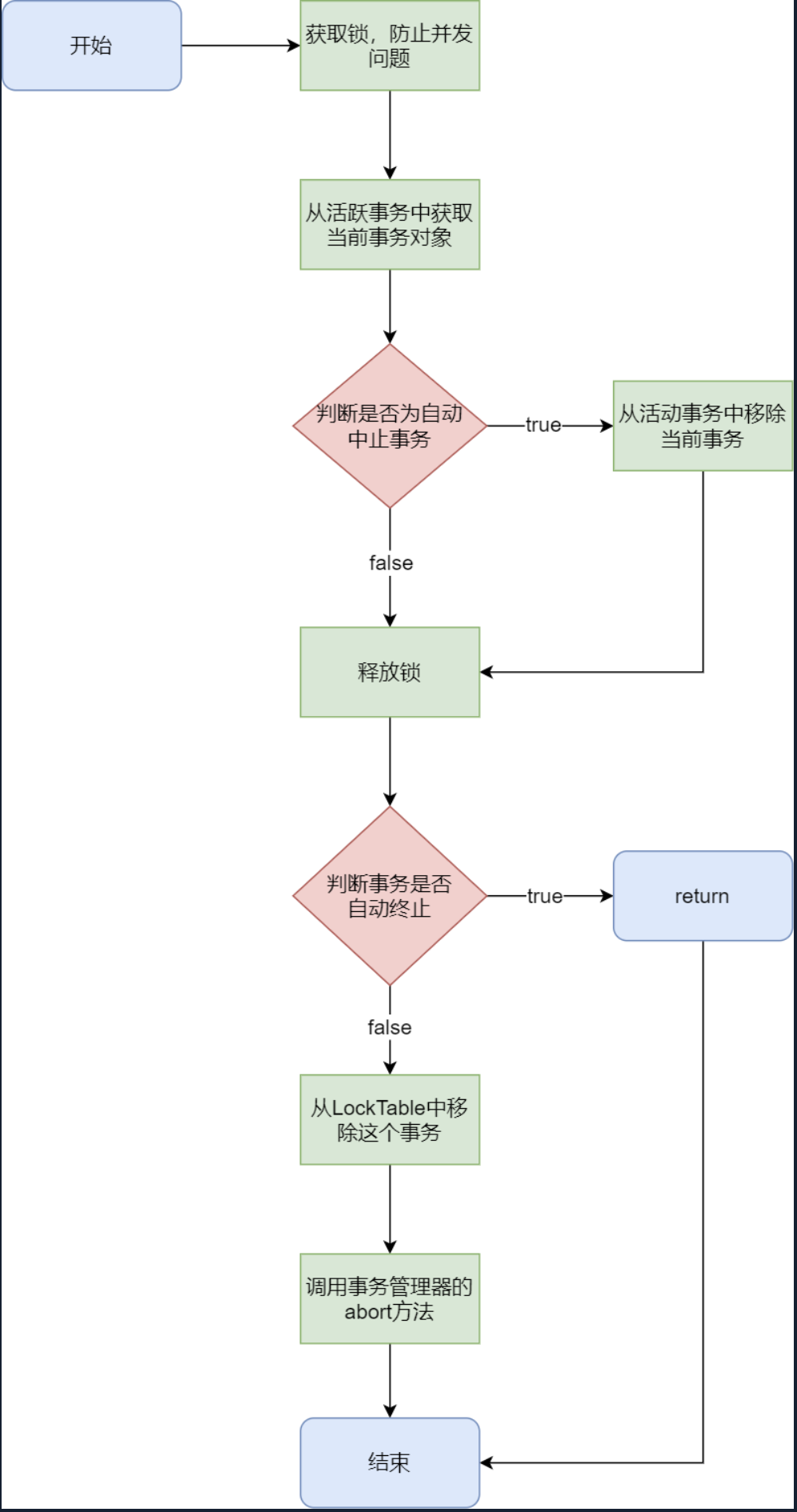
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void remove (long xid) { lock.lock(); try { List<Long> l = x2u.get(xid); if (l != null ) { while (l.size() > 0 ) { Long uid = l.remove(0 ); selectNewXID(uid); } } waitU.remove(xid); x2u.remove(xid); waitLock.remove(xid); } finally { lock.unlock(); } }
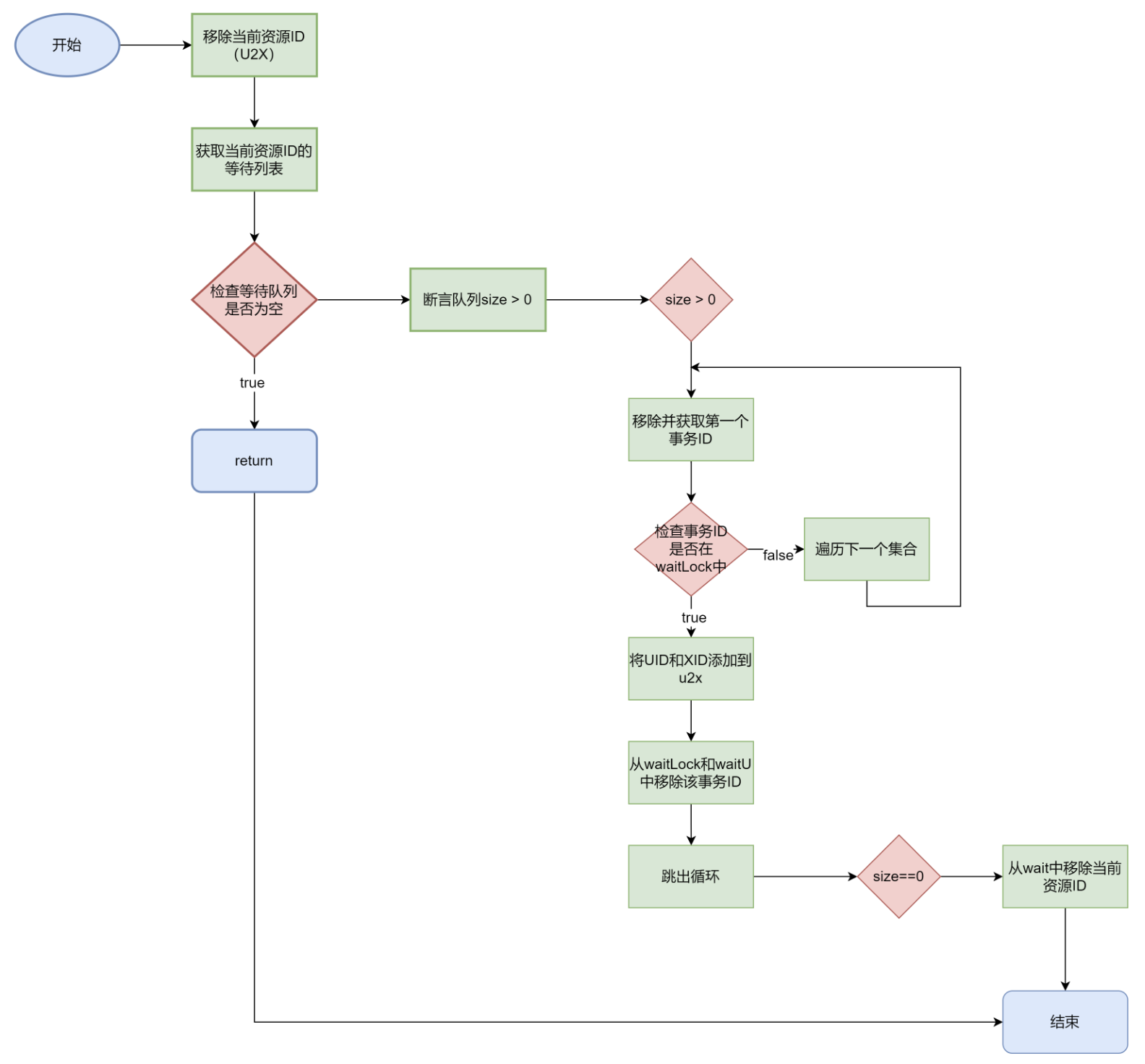
selectNewXID()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private void selectNewXID (long uid) { u2x.remove(uid); List<Long> l = wait.get(uid); if (l == null ) return ; assert l.size() > 0 ; while (l.size() > 0 ) { long xid = l.remove(0 ); if (!waitLock.containsKey(xid)) { continue ; } else { u2x.put(uid, xid); Lock lo = waitLock.remove(xid); waitU.remove(xid); lo.unlock(); break ; } } if (l.size() == 0 ) wait.remove(uid); }
VM的实现 VM的基本定义 VM 层通过 VersionManager 接口,向上层提供功能,如下:
1 2 3 4 5 6 7 8 9 public interface VersionManager { byte [] read(long xid, long uid) throws Exception; long insert (long xid, byte [] data) throws Exception; boolean delete (long xid, long uid) throws Exception; long begin (int level) ; void commit (long xid) throws Exception; void abort (long xid) ; }
同时,VM 的实现类还被设计为 **Entry**** **的缓存,需要继承** AbstractCache<Entry>**。需要实现的获取到缓存和从缓存释放的方法很简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Override protected Entry getForCache (long uid) throws Exception { Entry entry = Entry.loadEntry(this , uid); if (entry == null ) { throw Error.NullEntryException; } return entry; } @Override protected void releaseForCache (Entry entry) { entry.remove(); }
具体实现 begin()开启一个事务,并初始化事务的结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Override public long begin (int level) { lock.lock(); try { long xid = tm.begin(); Transaction t = Transaction.newTransaction(xid, level, activeTransaction); activeTransaction.put(xid, t); return xid; } finally { lock.unlock(); } } public static Transaction newTransaction (long xid, int level, Map<Long, Transaction> active) { Transaction t = new Transaction (); t.xid = xid; t.level = level; if (level != 0 ) { t.snapshot = new HashMap <>(); for (Long x : active.keySet()) { t.snapshot.put(x, true ); } } return t; }
commit()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Override public void commit (long xid) throws Exception { lock.lock(); Transaction t = activeTransaction.get(xid); lock.unlock(); try { if (t.err != null ) { throw t.err; } } catch (NullPointerException n) { System.out.println(xid); System.out.println(activeTransaction.keySet()); Panic.panic(n); } lock.lock(); activeTransaction.remove(xid); lock.unlock(); lt.remove(xid); tm.commit(xid); }
abort()abort 事务的方法则有两种,手动和自动。手动指的是调用 **abort()** 方法,而自动,则是在事务被检测出出现死锁时,会自动撤销回滚事务;或者出现版本跳跃时,也会自动回滚
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Override public void abort (long xid) { internAbort(xid, false ); } private void internAbort (long xid, boolean autoAborted) { lock.lock(); Transaction t = activeTransaction.get(xid); if (!autoAborted) { activeTransaction.remove(xid); } lock.unlock(); if (t.autoAborted) return ; lt.remove(xid); tm.abort(xid); }
read()read() 方法读取一个 entry,需要注意判断可见性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Override public byte [] read(long xid, long uid) throws Exception { lock.lock(); Transaction t = activeTransaction.get(xid); lock.unlock(); if (t.err != null ) { throw t.err; } Entry entry = null ; try { entry = super .get(uid); } catch (Exception e) { if (e == Error.NullEntryException) { return null ; } else { throw e; } } try { if (Visibility.isVisible(tm, t, entry)) { return entry.data(); } else { return null ; } } finally { entry.release(); } }
insert()将数据包裹成 Entry,然后交给 DM 插入即可
1 2 3 4 5 6 7 8 9 10 11 12 13 @Override public long insert (long xid, byte [] data) throws Exception { lock.lock(); Transaction t = activeTransaction.get(xid); lock.unlock(); if (t.err != null ) { throw t.err; } byte [] raw = Entry.wrapEntryRaw(xid, data); return dm.insert(xid, raw); }
delete()
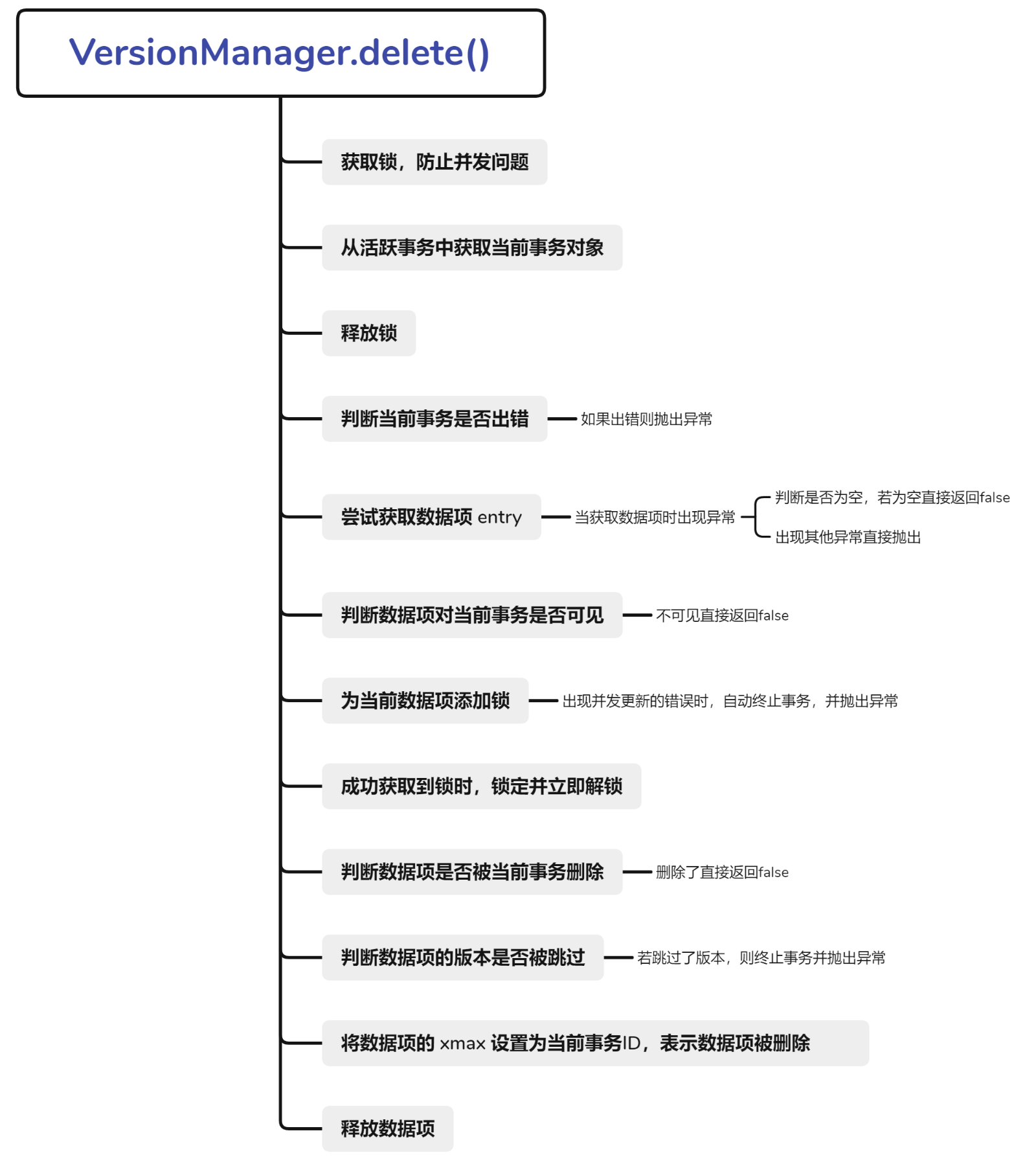
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 @Override public boolean delete (long xid, long uid) throws Exception { lock.lock(); Transaction t = activeTransaction.get(xid); lock.unlock(); if (t.err != null ) { throw t.err; } Entry entry = null ; try { entry = super .get(uid); } catch (Exception e) { if (e == Error.NullEntryException) { return false ; } else { throw e; } } try { if (!Visibility.isVisible(tm, t, entry)) { return false ; } Lock l = null ; try { l = lt.add(xid, uid); } catch (Exception e) { t.err = Error.ConcurrentUpdateException; internAbort(xid, true ); t.autoAborted = true ; throw t.err; } if (l != null ) { l.lock(); l.unlock(); } if (entry.getXmax() == xid) { return false ; } if (Visibility.isVersionSkip(tm, t, entry)) { t.err = Error.ConcurrentUpdateException; internAbort(xid, true ); t.autoAborted = true ; throw t.err; } entry.setXmax(xid); return true ; } finally { entry.release(); } }
Index Manager (IM) 索引管理器 前言
IM,即 Index Manager,索引管理器,为 MYDB 提供了基于 B+ 树的聚簇索引。目前 MYDB 只支持基于索引查找数据,不支持全表扫描。感兴趣的同学可以自行实现。
在依赖关系图中可以看到,IM 直接基于 DM,而没有基于 VM。索引的数据被直接插入数据库文件中,而不需要经过版本管理。
本节不赘述 B+ 树算法,更多描述实现。
基本结构 1 2 [LeafFlag][KeyNumber][SiblingUid] [Son0][Key0][Son1][Key1]...[SonN][KeyN]
**[LeafFlag]**:标记该节点是否为叶子节点
**[KeyNumber]**:该节点中 key 的个数
**[SiblingUid]**:是其兄弟节点存储在 DM 中的 UID,用于实现节点的连接
[**SonN] [KeyN]**:后续穿插的子节点,最后一个 Key 始终为 MAX_VALUE,以方便查找
Node具体实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 public class Node { static final int IS_LEAF_OFFSET = 0 ; static final int NO_KEYS_OFFSET = IS_LEAF_OFFSET + 1 ; static final int SIBLING_OFFSET = NO_KEYS_OFFSET + 2 ; static final int NODE_HEADER_SIZE = SIBLING_OFFSET + 8 ; static final int BALANCE_NUMBER = 32 ; static final int NODE_SIZE = NODE_HEADER_SIZE + (2 * 8 ) * (BALANCE_NUMBER * 2 + 2 ); static void setRawIsLeaf (SubArray raw, boolean isLeaf) { if (isLeaf) { raw.raw[raw.start + IS_LEAF_OFFSET] = (byte ) 1 ; } else { raw.raw[raw.start + IS_LEAF_OFFSET] = (byte ) 0 ; } } static boolean getRawIfLeaf (SubArray raw) { return raw.raw[raw.start + IS_LEAF_OFFSET] == (byte ) 1 ; } static void setRawNoKeys (SubArray raw, int noKeys) { System.arraycopy(Parser.short2Byte((short ) noKeys), 0 , raw.raw, raw.start + NO_KEYS_OFFSET, 2 ); } static int getRawNoKeys (SubArray raw) { return (int ) Parser.parseShort(Arrays.copyOfRange(raw.raw, raw.start + NO_KEYS_OFFSET, raw.start + NO_KEYS_OFFSET + 2 )); } static void setRawSibling (SubArray raw, long sibling) { System.arraycopy(Parser.long2Byte(sibling), 0 , raw.raw, raw.start + SIBLING_OFFSET, 8 ); } static long getRawSibling (SubArray raw) { return Parser.parseLong(Arrays.copyOfRange(raw.raw, raw.start + SIBLING_OFFSET, raw.start + SIBLING_OFFSET + 8 )); } static void setRawKthSon (SubArray raw, long uid, int kth) { int offset = raw.start + NODE_HEADER_SIZE + kth * (8 * 2 ); System.arraycopy(Parser.long2Byte(uid), 0 , raw.raw, offset, 8 ); } static long getRawKthSon (SubArray raw, int kth) { int offset = raw.start + NODE_HEADER_SIZE + kth * (8 * 2 ); return Parser.parseLong(Arrays.copyOfRange(raw.raw, offset, offset + 8 )); } static void setRawKthKey (SubArray raw, long key, int kth) { int offset = raw.start + NODE_HEADER_SIZE + kth * (8 * 2 ) + 8 ; System.arraycopy(Parser.long2Byte(key), 0 , raw.raw, offset, 8 ); } static long getRawKthKey (SubArray raw, int kth) { int offset = raw.start + NODE_HEADER_SIZE + kth * (8 * 2 ) + 8 ; return Parser.parseLong(Arrays.copyOfRange(raw.raw, offset, offset + 8 )); } static void copyRawFromKth (SubArray from, SubArray to, int kth) { int offset = from.start + NODE_HEADER_SIZE + kth * (8 * 2 ); System.arraycopy(from.raw, offset, to.raw, to.start + NODE_HEADER_SIZE, from.end - offset); } }
newRootRaw()1 2 3 4 5 6 7 8 9 10 11 12 [LeafFlag: 0] [KeyNumber: 2] [SiblingUid: 0] [Son0: left][Key0: key][Son1: right][Key1: MAX_ VALUE] 注:一个简单的演示 (key) / \ \ \
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static byte [] newRootRaw(long left, long right, long key) { SubArray raw = new SubArray (new byte [NODE_SIZE], 0 , NODE_SIZE); setRawIsLeaf(raw, false ); setRawNoKeys(raw, 2 ); setRawSibling(raw, 0 ); setRawKthSon(raw, left, 0 ); setRawKthKey(raw, key, 0 ); setRawKthSon(raw, right, 1 ); setRawKthKey(raw, Long.MAX_VALUE, 1 ); return raw.raw; }
newNilRootRaw()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static byte [] newNilRootRaw() { SubArray raw = new SubArray (new byte [NODE_SIZE], 0 , NODE_SIZE); setRawIsLeaf(raw, true ); setRawNoKeys(raw, 0 ); setRawSibling(raw, 0 ); return raw.raw; }
searchNext()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class SearchNextRes { long uid; long siblingUid; } public SearchNextRes searchNext (long key) { dataItem.rLock(); try { SearchNextRes res = new SearchNextRes (); int noKeys = getRawNoKeys(raw); for (int i = 0 ; i < noKeys; i++) { long ik = getRawKthKey(raw, i); if (key < ik) { res.uid = getRawKthSon(raw, i); res.siblingUid = 0 ; return res; } } res.uid = 0 ; res.siblingUid = getRawSibling(raw); return res; } finally { dataItem.rUnLock(); } }
LeafSearchRangeRes()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class LeafSearchRangeRes { List<Long> uids; long siblingUid; } public LeafSearchRangeRes leafSearchRange (long leftKey, long rightKey) { dataItem.rLock(); try { int noKeys = getRawNoKeys(raw); int kth = 0 ; while (kth < noKeys) { long ik = getRawKthKey(raw, kth); if (ik >= leftKey) { break ; } kth++; } List<Long> uids = new ArrayList <>(); while (kth < noKeys) { long ik = getRawKthKey(raw, kth); if (ik <= rightKey) { uids.add(getRawKthSon(raw, kth)); kth++; } else { break ; } } long siblingUid = 0 ; if (kth == noKeys) { siblingUid = getRawSibling(raw); } LeafSearchRangeRes res = new LeafSearchRangeRes (); res.uids = uids; res.siblingUid = siblingUid; return res; } finally { dataItem.rUnLock(); } }
insertAndSplit()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class InsertAndSplitRes { long siblingUid, newSon, newKey; } public InsertAndSplitRes insertAndSplit (long uid, long key) throws Exception { boolean success = false ; Exception err = null ; InsertAndSplitRes res = new InsertAndSplitRes (); dataItem.before(); try { success = insert(uid, key); if (!success) { res.siblingUid = getRawSibling(raw); return res; } if (needSplit()) { try { SplitRes r = split(); res.newSon = r.newSon; res.newKey = r.newKey; return res; } catch (Exception e) { err = e; throw e; } } else { return res; } } finally { if (err == null && success) { dataItem.after(TransactionManagerImpl.SUPER_XID); } else { dataItem.unBefore(); } } }
insert()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 private boolean insert (long uid, long key) { int noKeys = getRawNoKeys(raw); int kth = 0 ; while (kth < noKeys) { long ik = getRawKthKey(raw, kth); if (ik < key) { kth++; } else { break ; } } if (kth == noKeys && getRawSibling(raw) != 0 ) return false ; if (getRawIfLeaf(raw)) { shiftRawKth(raw, kth); setRawKthKey(raw, key, kth); setRawKthSon(raw, uid, kth); setRawNoKeys(raw, noKeys + 1 ); } else { long kk = getRawKthKey(raw, kth); setRawKthKey(raw, key, kth); shiftRawKth(raw, kth + 1 ); setRawKthKey(raw, kk, kth + 1 ); setRawKthSon(raw, uid, kth + 1 ); setRawNoKeys(raw, noKeys + 1 ); } return true ; }
split()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class SplitRes { long newSon, newKey; } private SplitRes split () throws Exception { SubArray nodeRaw = new SubArray (new byte [NODE_SIZE], 0 , NODE_SIZE); setRawIsLeaf(nodeRaw, getRawIfLeaf(raw)); setRawNoKeys(nodeRaw, BALANCE_NUMBER); setRawSibling(nodeRaw, getRawSibling(raw)); copyRawFromKth(raw, nodeRaw, BALANCE_NUMBER); long son = tree.dm.insert(TransactionManagerImpl.SUPER_XID, nodeRaw.raw); setRawNoKeys(raw, BALANCE_NUMBER); setRawSibling(raw, son); SplitRes res = new SplitRes (); res.newSon = son; res.newKey = getRawKthKey(nodeRaw, 0 ); return res; }
Table Manager (TBM) 表结构管理器 本章概述 TBM,即表管理器的实现。TBM 实现了对字段结构和表结构的管理。同时简要介绍 MYDB 使用的类 SQL 语句的解析。
SQL 解析器 **Parser** 实现了对类 **SQL** 语句的结构化解析,将语句中包含的信息封装为对应语句的类,这些类可见 **top.guoziyang.mydb.backend.parser.statement** 包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 < begin statement> begin [isolation level (read committedrepeatable read)] begin isolation level read committed < commit statement> commit < abort statement> abort < create statement> create table < table name> < field name> < field type> < field name> < field type> ... < field name> < field type> [(index < field name list> )] create table students id int32, name string, age int32, (index id name) < drop statement> drop table < table name> drop table students < select statement> select (* < field name list> ) from < table name> [< where statement> ] select * from student where id = 1 select name from student where id > 1 and id < 4 select name, age, id from student where id = 12 < insert statement> insert into < table name> values < value list> insert into student values 5 "Zhang Yuanjia" 22 < delete statement> delete from < table name> < where statement> delete from student where name = "Zhang Yuanjia" < update statement> update < table name> set < field name>= < value > [< where statement> ] update student set name = "ZYJ" where id = 5 < where statement> where < field name> (> <= ) < value > [(andor) < field name> (> <= ) < value > ] where age > 10 or age < 3 < field name> < table name> [a- zA- Z][a- zA- Z0-9 _]* < field type> int32 int64 string < value > .*
Tokenizer类:
Tokenizer类用于对语句进行逐字节解析,根据空白符或者特定的词法规则,将语句切割成多个token。
提供了peek()和pop()方法,方便取出Token进行解析。
具体的切割实现在内部,不在此段内容中赘述。
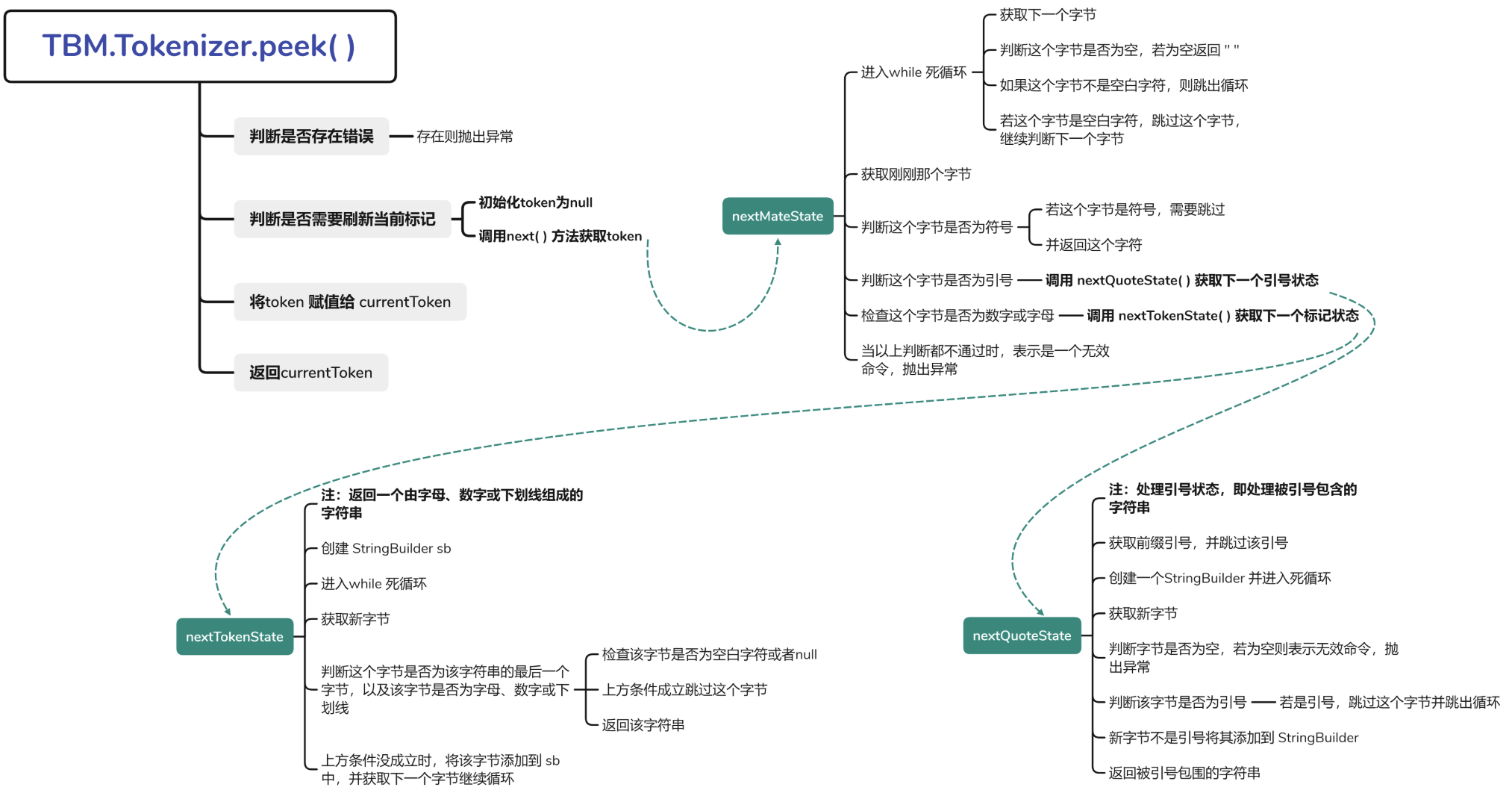
peek()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public String peek () throws Exception { if (err != null ) { throw err; } if (flushToken) { String token = null ; try { token = next(); } catch (Exception e) { err = e; throw e; } currentToken = token; flushToken = false ; } return currentToken; } private String next () throws Exception { if (err != null ) { throw err; } return nextMetaState(); } private String nextMetaState () throws Exception { while (true ) { Byte b = peekByte(); if (b == null ) { return "" ; } if (!isBlank(b)) { break ; } popByte(); } byte b = peekByte(); if (isSymbol(b)) { popByte(); return new String (new byte []{b}); } else if (b == '"' || b == '\'' ) { return nextQuoteState(); } else if (isAlphaBeta(b) || isDigit(b)) { return nextTokenState(); } else { err = Error.InvalidCommandException; throw err; } } private String nextTokenState () throws Exception { StringBuilder sb = new StringBuilder (); while (true ) { Byte b = peekByte(); if (b == null || !(isAlphaBeta(b) || isDigit(b) || b == '_' )) { if (b != null && isBlank(b)) { popByte(); } return sb.toString(); } sb.append(new String (new byte []{b})); popByte(); } } private String nextQuoteState () throws Exception { byte quote = peekByte(); popByte(); StringBuilder sb = new StringBuilder (); while (true ) { Byte b = peekByte(); if (b == null ) { err = Error.InvalidCommandException; throw err; } if (b == quote) { popByte(); break ; } sb.append(new String (new byte []{b})); popByte(); } return sb.toString(); }
pop()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void pop () { flushToken = true ; } private void popByte () { pos++; if (pos > stat.length) { pos = stat.length; } }
Parser类
Parser类直接对外提供了Parse(byte[] statement)方法,用于解析语句。
解析过程核心是调用Tokenizer类来分割Token,并根据词法规则将Token包装成具体的Statement类,并返回。
解析过程相对简单,仅根据第一个Token来区分语句类型,并分别处理。
解析过程自己查看几遍源码即可,这里不多赘述
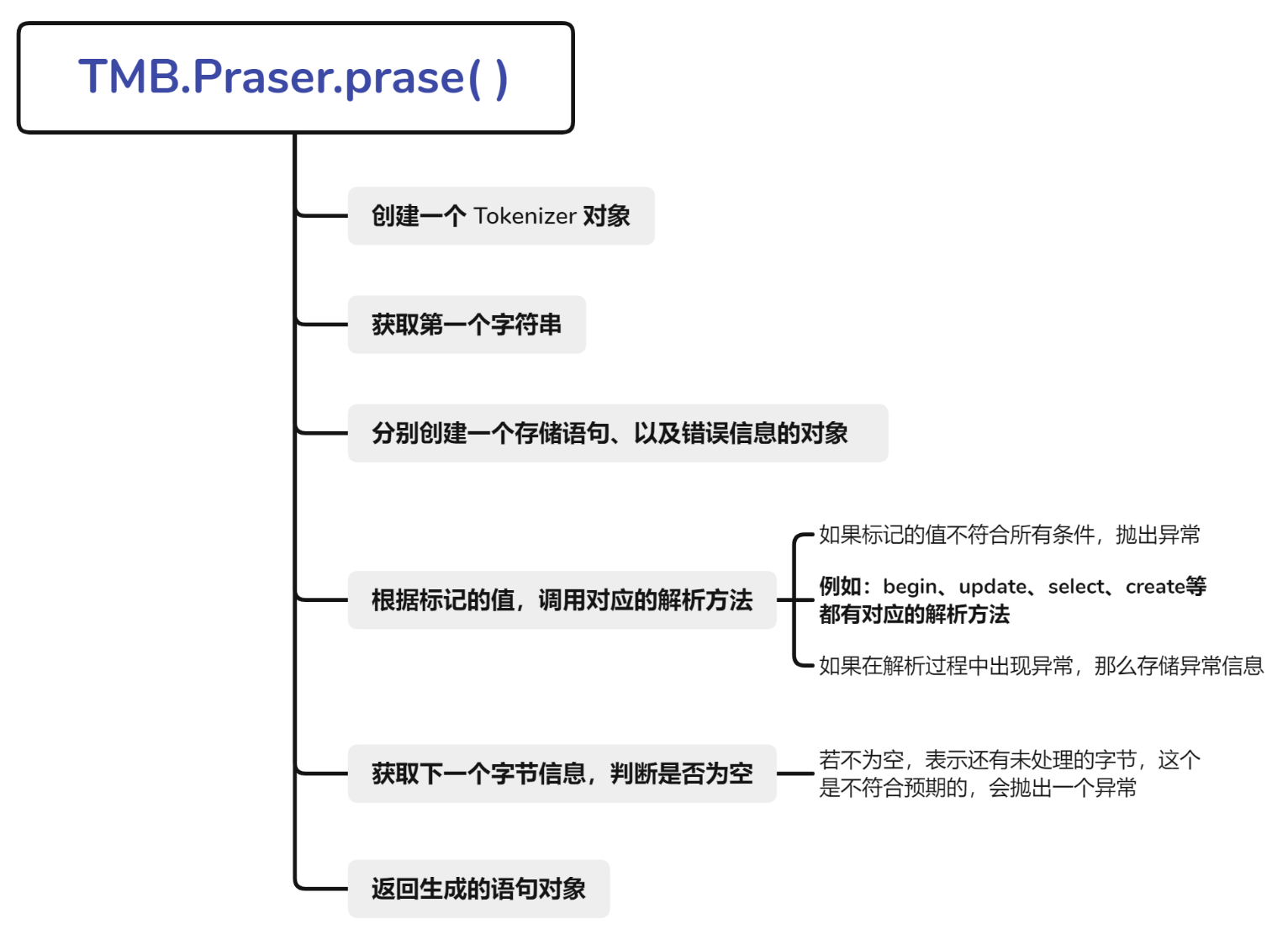
parse()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public static Object Parse (byte [] statement) throws Exception { Tokenizer tokenizer = new Tokenizer (statement); String token = tokenizer.peek(); tokenizer.pop(); Object stat = null ; Exception statErr = null ; try { switch (token) { case "begin" : stat = parseBegin(tokenizer); break ; case "commit" : stat = parseCommit(tokenizer); break ; case "abort" : stat = parseAbort(tokenizer); break ; case "create" : stat = parseCreate(tokenizer); break ; case "drop" : stat = parseDrop(tokenizer); break ; case "select" : stat = parseSelect(tokenizer); break ; case "insert" : stat = parseInsert(tokenizer); break ; case "delete" : stat = parseDelete(tokenizer); break ; case "update" : stat = parseUpdate(tokenizer); break ; case "show" : stat = parseShow(tokenizer); break ; default : throw Error.InvalidCommandException; } } catch (Exception e) { statErr = e; } try { String next = tokenizer.peek(); if (!"" .equals(next)) { byte [] errStat = tokenizer.errStat(); statErr = new RuntimeException ("Invalid statement: " + new String (errStat)); } } catch (Exception e) { e.printStackTrace(); byte [] errStat = tokenizer.errStat(); statErr = new RuntimeException ("Invalid statement: " + new String (errStat)); } if (statErr != null ) { throw statErr; } return stat; }
字段与表管理 注意,这里的字段与表管理,不是管理各个条目中不同的字段的数值等信息,而是管理表和字段的结构数据,例如表名、表字段信息和字段索引等。
结构数据
数据存储结构: 表和字段的信息以二进制形式存储在数据库的 Entry 中。字段信息表示: 字段的二进制表示包含字段名(FieldName)、字段类型(TypeName)和索引UID(IndexUid)。
字段名和字段类型以及其他信息都以字节形式的字符串存储。
**[FieldName] [TypeName] [IndexUid]**为了明确字符串的存储边界,采用了一种规定的字符串存储方式,即在字符串数据之前存储了字符串的长度信息。
**[StringLength] [StringData]**
字段类型限定: 字段的类型被限定为 int32、int64 和 string 类型。索引表示: 如果字段被索引,则IndexUid指向了索引二叉树的根节点;否则该字段的IndexUid为0。读取和解析: 通过唯一标识符(UID)从虚拟内存(VM)中读取字段信息,并根据上述结构解析该信息。
Table 基本定义
**[TableName] [NextTable] [Field1Uid][Field2Uid]...[FieldNUid]**1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Table { TableManager tbm; long uid; String name; byte status; long nextUid; List<Field> fields = new ArrayList <>(); }
createTable()
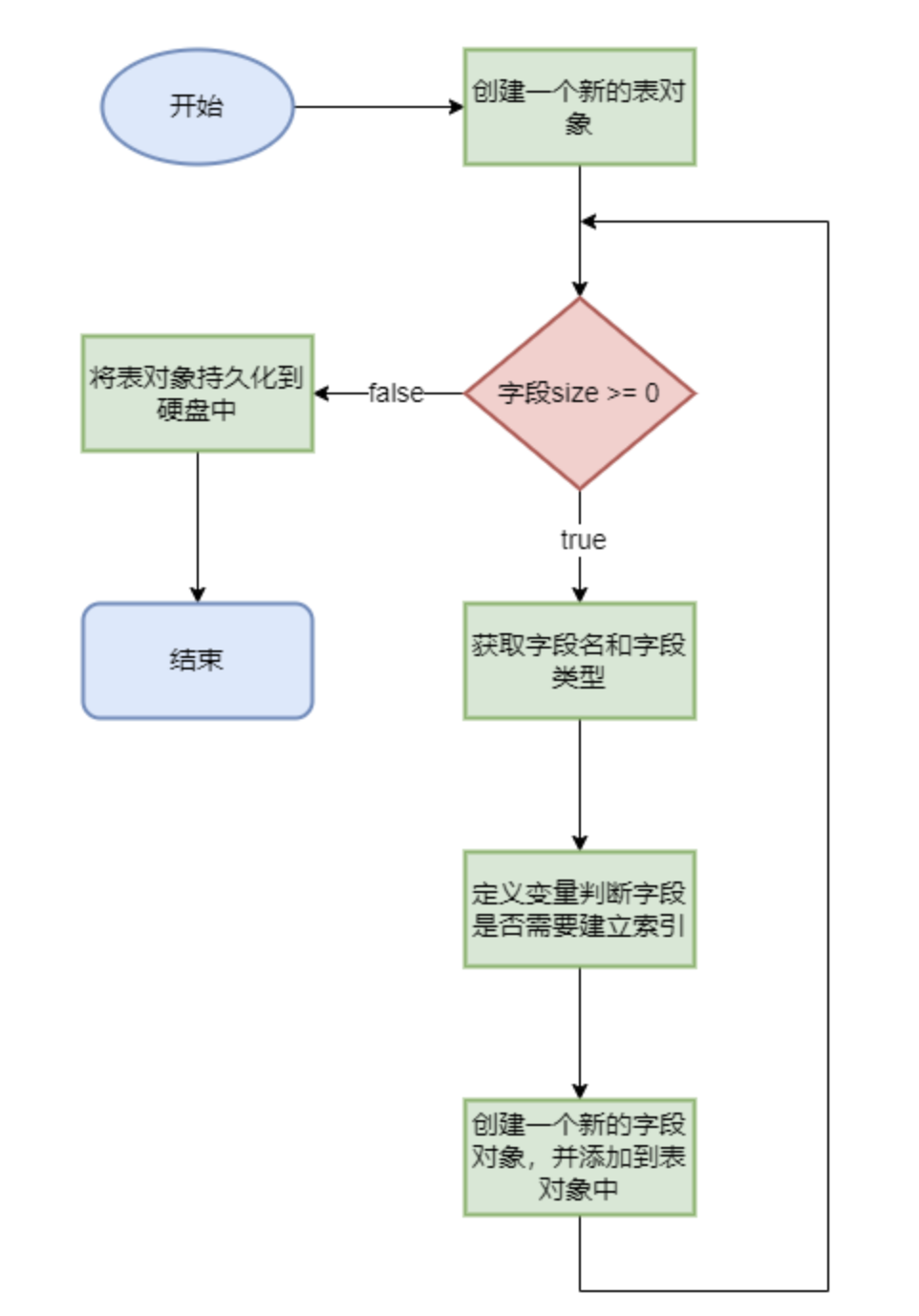
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public static Table createTable (TableManager tbm, long nextUid, long xid, Create create) throws Exception { Table tb = new Table (tbm, create.tableName, nextUid); for (int i = 0 ; i < create.fieldName.length; i++) { String fieldName = create.fieldName[i]; String fieldType = create.fieldType[i]; boolean indexed = false ; for (int j = 0 ; j < create.index.length; j++) { if (fieldName.equals(create.index[j])) { indexed = true ; break ; } } tb.fields.add(Field.createField(tb, xid, fieldName, fieldType, indexed)); } return tb.persistSelf(xid); }
persistSelf()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private Table persistSelf (long xid) throws Exception { byte [] nameRaw = Parser.string2Byte(name); byte [] nextRaw = Parser.long2Byte(nextUid); byte [] fieldRaw = new byte [0 ]; for (Field field : fields) { fieldRaw = Bytes.concat(fieldRaw, Parser.long2Byte(field.uid)); } uid = ((TableManagerImpl) tbm).vm.insert(xid, Bytes.concat(nameRaw, nextRaw, fieldRaw)); return this ; }
loadTable()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static Table loadTable (TableManager tbm, long uid) { byte [] raw = null ; try { raw = ((TableManagerImpl) tbm).vm.read(TransactionManagerImpl.SUPER_XID, uid); } catch (Exception e) { Panic.panic(e); } assert raw != null ; Table tb = new Table (tbm, uid); return tb.parseSelf(raw); }
parseSelf()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private Table parseSelf (byte [] raw) { int position = 0 ; ParseStringRes res = Parser.parseString(raw); name = res.str; position += res.next; nextUid = Parser.parseLong(Arrays.copyOfRange(raw, position, position + 8 )); position += 8 ; while (position < raw.length) { long uid = Parser.parseLong(Arrays.copyOfRange(raw, position, position + 8 )); position += 8 ; fields.add(Field.loadField(this , uid)); } return this ; }
Field 基本定义
**[FieldName] [TypeName] [IndexUid]**1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Field { long uid; private Table tb; String fieldName; String fieldType; private long index; private BPlusTree bt; }
createField()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static Field createField (Table tb, long xid, String fieldName, String fieldType, boolean indexed) throws Exception { typeCheck(fieldType); Field f = new Field (tb, fieldName, fieldType, 0 ); if (indexed) { long index = BPlusTree.create(((TableManagerImpl) tb.tbm).dm); BPlusTree bt = BPlusTree.load(index, ((TableManagerImpl) tb.tbm).dm); f.index = index; f.bt = bt; } f.persistSelf(xid); return f; } private static void typeCheck (String fieldType) throws Exception { if (!"int32" .equals(fieldType) && !"int64" .equals(fieldType) && !"string" .equals(fieldType)) { throw Error.InvalidFieldException; } }
persistSelf()1 2 3 4 5 6 7 8 9 10 11 12 13 14 private void persistSelf (long xid) throws Exception { byte [] nameRaw = Parser.string2Byte(fieldName); byte [] typeRaw = Parser.string2Byte(fieldType); byte [] indexRaw = Parser.long2Byte(index); this .uid = ((TableManagerImpl) tb.tbm).vm.insert(xid, Bytes.concat(nameRaw, typeRaw, indexRaw)); }
loadField()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static Field loadField (Table tb, long uid) { byte [] raw = null ; try { raw = ((TableManagerImpl) tb.tbm).vm.read(TransactionManagerImpl.SUPER_XID, uid); } catch (Exception e) { Panic.panic(e); } assert raw != null ; return new Field (uid, tb).parseSelf(raw); }
parseSelf()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private Field parseSelf (byte [] raw) { int position = 0 ; ParseStringRes res = Parser.parseString(raw); fieldName = res.str; position += res.next; res = Parser.parseString(Arrays.copyOfRange(raw, position, raw.length)); fieldType = res.str; position += res.next; this .index = Parser.parseLong(Arrays.copyOfRange(raw, position, position + 8 )); if (index != 0 ) { try { bt = BPlusTree.load(index, ((TableManagerImpl) tb.tbm).dm); } catch (Exception e) { Panic.panic(e); } } return this ; }
Where查询条件 parseWhere()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 private List<Long> parseWhere (Where where) throws Exception { long l0 = 0 , r0 = 0 , l1 = 0 , r1 = 0 ; boolean single = false ; Field fd = null ; if (where == null ) { for (Field field : fields) { if (field.isIndexed()) { fd = field; break ; } } l0 = 0 ; r0 = Long.MAX_VALUE; single = true ; } else { for (Field field : fields) { if (field.fieldName.equals(where.singleExp1.field)) { if (!field.isIndexed()) { throw Error.FieldNotIndexedException; } fd = field; break ; } } if (fd == null ) { throw Error.FieldNotFoundException; } CalWhereRes res = calWhere(fd, where); l0 = res.l0; r0 = res.r0; l1 = res.l1; r1 = res.r1; single = res.single; } List<Long> uids = fd.search(l0, r0); if (!single) { List<Long> tmp = fd.search(l1, r1); uids.addAll(tmp); } return uids; }
calWhere()Booter 前言
启动信息管理
MYDB的启动信息存储在bt 文件中,其中所需的信息只有一个,即头表的UID。
Booter 类提供了load 和update 两个方法,用于加载和更新启动信息。update 方法在修改bt 文件内容时,采取了一种保证原子性的策略,即先将内容写入一个临时文件bt_tmp 中,然后通过操作系统的重命名操作将临时文件重命名为bt 文件。通过这种方式,利用操作系统重命名文件的原子性,来确保对bt 文件的修改操作是原子的,从而保证了启动信息的一致性和正确性。
基本定义 1 2 3 4 5 6 7 8 9 10 11 12 public class Booter { public static final String BOOTER_SUFFIX = ".bt" ; public static final String BOOTER_TMP_SUFFIX = ".bt_tmp" ; String path; File file; }
create() and open()通过创建或打开启动信息文件,来进行数据库的校验
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public static Booter create (String path) { removeBadTmp(path); File f = new File (path + BOOTER_SUFFIX); try { if (!f.createNewFile()) { Panic.panic(Error.FileExistsException); } } catch (Exception e) { Panic.panic(e); } if (!f.canRead() || !f.canWrite()) { Panic.panic(Error.FileCannotRWException); } return new Booter (path, f); } public static Booter open (String path) { removeBadTmp(path); File f = new File (path + BOOTER_SUFFIX); if (!f.exists()) { Panic.panic(Error.FileNotExistsException); } if (!f.canRead() || !f.canWrite()) { Panic.panic(Error.FileCannotRWException); } return new Booter (path, f); } private static void removeBadTmp (String path) { new File (path + BOOTER_TMP_SUFFIX).delete(); }
load()加载文件启动信息文件
1 2 3 4 5 6 7 8 9 10 public byte [] load() { byte [] buf = null ; try { buf = Files.readAllBytes(file.toPath()); } catch (IOException e) { Panic.panic(e); } return buf; }
update()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public void update (byte [] data) { File tmp = new File (path + BOOTER_TMP_SUFFIX); try { tmp.createNewFile(); } catch (Exception e) { Panic.panic(e); } if (!tmp.canRead() || !tmp.canWrite()) { Panic.panic(Error.FileCannotRWException); } try (FileOutputStream out = new FileOutputStream (tmp)) { out.write(data); out.flush(); } catch (IOException e) { Panic.panic(e); } try { Files.move(tmp.toPath(), new File (path + BOOTER_SUFFIX).toPath(), StandardCopyOption.REPLACE_EXISTING); } catch (IOException e) { Panic.panic(e); } file = new File (path + BOOTER_SUFFIX); if (!file.canRead() || !file.canWrite()) { Panic.panic(Error.FileCannotRWException); } }
TableManager 基本定义
TableManager 中的方法直接返回执行结果,比如错误信息或者可读的结果信息的字节数组。这些方法的实现相对简单,主要是调用(VM)相关的方法来完成数据库操作。
在创建新表时,采用了头插法,即每次创建表都将新表插入到链表的头部。这意味着最新创建的表会成为链表的第一个元素。由于使用了头插法,每次创建表都会改变表链表的头部,因此需要更新Booter 文件,以便记录新的头表的UID。
在创建TBM对象时,会初始化表信息1 2 3 4 5 6 7 8 9 10 11 12 13 14 public interface TableManager { BeginRes begin (Begin begin) ; byte [] commit(long xid) throws Exception; byte [] abort(long xid); byte [] show(long xid); byte [] create(long xid, Create create) throws Exception; byte [] insert(long xid, Insert insert) throws Exception; byte [] read(long xid, Select select) throws Exception; byte [] update(long xid, Update update) throws Exception; byte [] delete(long xid, Delete delete) throws Exception; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class TableManagerImpl implements TableManager { VersionManager vm; DataManager dm; private Booter booter; private Map<String, Table> tableCache; private Map<Long, List<Table>> xidTableCache; private Lock lock; TableManagerImpl(VersionManager vm, DataManager dm, Booter booter) { this .vm = vm; this .dm = dm; this .booter = booter; this .tableCache = new HashMap <>(); this .xidTableCache = new HashMap <>(); lock = new ReentrantLock (); loadTables(); } }
loadTables()1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private void loadTables () { long uid = firstTableUid(); while (uid != 0 ) { Table tb = Table.loadTable(this , uid); uid = tb.nextUid; tableCache.put(tb.name, tb); } } private long firstTableUid () { byte [] raw = booter.load(); return Parser.parseLong(raw); }
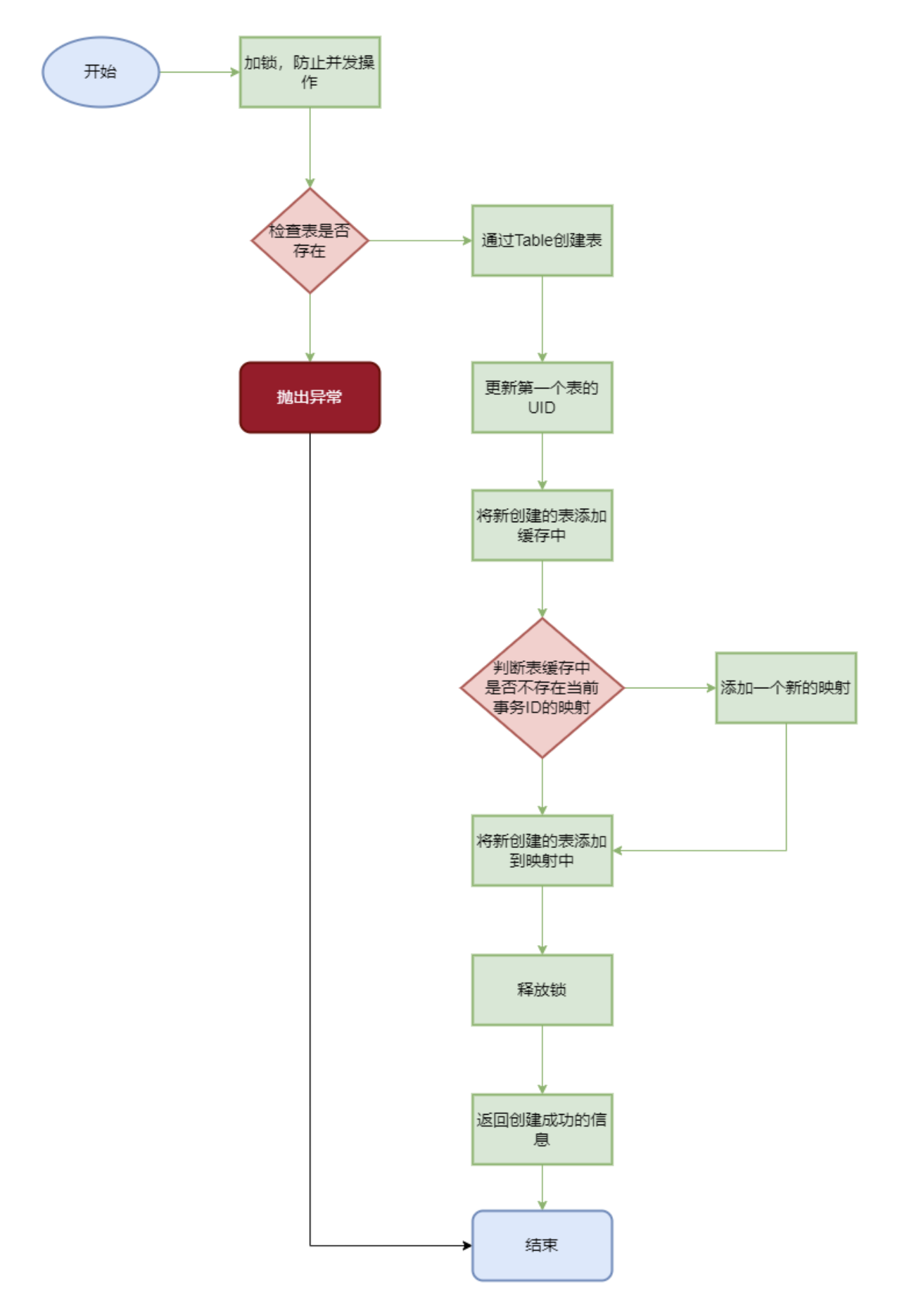
create()这里主要讲解一下 create方法,其他方法都是调用 VM 层
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Override public byte [] create(long xid, Create create) throws Exception { lock.lock(); try { if (tableCache.containsKey(create.tableName)) { throw Error.DuplicatedTableException; } Table table = Table.createTable(this , firstTableUid(), xid, create); updateFirstTableUid(table.uid); tableCache.put(create.tableName, table); if (!xidTableCache.containsKey(xid)) { xidTableCache.put(xid, new ArrayList <>()); } xidTableCache.get(xid).add(table); return ("create " + create.tableName).getBytes(); } finally { lock.unlock(); } }
服务端客户端的实现及其通信规则 前言 在MYDB 中传输数据使用了一种特殊的二进制格式,用于客户端和通信端之间的通信。在数据的传输和接受之前,会通过Package进行数据的加密以及解密:
**[Flag] [Data]**若 flag 为 0,表示发送的是数据,那么 data 即为这份数据本身,err 就为空
若 flag 为 1,表示发送的是错误信息,那么 data 为空, err 为错误提示信息1 2 3 4 5 6 7 8 9 public class Package { byte [] data; Exception err; public Package (byte [] data, Exception err) { this .data = data; this .err = err; } }
Encoder 用于将数据加密成十六进制 数据,这样可以避免特殊字符造成的问题,并在信息末尾加上换行符。这样在发送和接受数据时,可以简单使用 BufferedReader 和 BufferedWrite进行读写数据;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Encoder { public byte [] encode(Package pkg) { if (pkg.getErr() != null ) { Exception err = pkg.getErr(); String msg = "Intern server error!" ; if (err.getMessage() != null ) { msg = err.getMessage(); } return Bytes.concat(new byte []{1 }, msg.getBytes()); } else { return Bytes.concat(new byte []{0 }, pkg.getData()); } } public Package decode (byte [] data) throws Exception { if (data.length < 1 ) { throw Error.InvalidPkgDataException; } if (data[0 ] == 0 ) { return new Package (Arrays.copyOfRange(data, 1 , data.length), null ); } else if (data[0 ] == 1 ) { return new Package (null , new RuntimeException (new String (Arrays.copyOfRange(data, 1 , data.length)))); } else { throw Error.InvalidPkgDataException; } } }
Transporter 编码之后的信息会通过 Transporter类,写入输出流发送出去;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class Transporter { private Socket socket; private BufferedReader reader; private BufferedWriter writer; public Transporter (Socket socket) throws IOException { this .socket = socket; this .reader = new BufferedReader (new InputStreamReader (socket.getInputStream())); this .writer = new BufferedWriter (new OutputStreamWriter (socket.getOutputStream())); } public void send (byte [] data) throws Exception { String raw = hexEncode(data); writer.write(raw); writer.flush(); } public byte [] receive() throws Exception { String line = reader.readLine(); if (line == null ) { close(); } return hexDecode(line); } public void close () throws IOException { writer.close(); reader.close(); socket.close(); } private String hexEncode (byte [] buf) { return Hex.encodeHexString(buf, true )+"\n" ; } private byte [] hexDecode(String buf) throws DecoderException { return Hex.decodeHex(buf); } }
Packager Packager 则是 Encoder 和 Transporter 的结合体,直接对外提供 send 和 receive 方法: bmn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Packager { private Transporter transpoter; private Encoder encoder; public Packager (Transporter transpoter, Encoder encoder) { this .transpoter = transpoter; this .encoder = encoder; } public void send (Package pkg) throws Exception { byte [] data = encoder.encode(pkg); transpoter.send(data); } public Package receive () throws Exception { byte [] data = transpoter.receive(); return encoder.decode(data); } public void close () throws Exception { transpoter.close(); } }
服务端和客户端的实现 Server 和 Client,都是使用了Java 的 socket;这一块内容属于 Java 网络编程的,可以通过 二哥的进阶之路 学习;
Server **Server**是一个服务器类,主要作用是监听指定的端口号,接受客户端的连接请求,并为每个连接请求创建一个新的线程来处理;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class Server { private int port; TableManager tbm; public Server (int port, TableManager tbm) { this .port = port; this .tbm = tbm; } public void start () { ServerSocket ss = null ; try { ss = new ServerSocket (port); } catch (IOException e) { e.printStackTrace(); return ; } System.out.println("Server listen to port: " + port); ThreadPoolExecutor tpe = new ThreadPoolExecutor (10 , 20 , 1L , TimeUnit.SECONDS, new ArrayBlockingQueue <>(100 ), new ThreadPoolExecutor .CallerRunsPolicy()); try { while (true ) { Socket socket = ss.accept(); Runnable worker = new HandleSocket (socket, tbm); tpe.execute(worker); } } catch (IOException e) { e.printStackTrace(); } finally { try { ss.close(); } catch (IOException ignored) { } } } }
HandleSocket HandleSocket 类实现了 **Runnable**** 接口,在建立连接后初始化 **Packager**,随后就循环接收来自客户端的数据并处理;主要通过 **Executor** 对象来执行 **SQL**语句,在接受、执行SQL语句的过程中发生异常的话,将会结束循环,并关闭 **Executor** **和 **Package**;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class HandleSocket implements Runnable { private Socket socket; private TableManager tbm; public HandleSocket (Socket socket, TableManager tbm) { this .socket = socket; this .tbm = tbm; } @Override public void run () { InetSocketAddress address = (InetSocketAddress) socket.getRemoteSocketAddress(); System.out.println("Establish connection: " + address.getAddress().getHostAddress() + ":" + address.getPort()); Packager packager = null ; try { Transporter t = new Transporter (socket); Encoder e = new Encoder (); packager = new Packager (t, e); } catch (IOException e) { e.printStackTrace(); try { socket.close(); } catch (IOException e1) { e1.printStackTrace(); } return ; } Executor exe = new Executor (tbm); while (true ) { Package pkg = null ; try { pkg = packager.receive(); } catch (Exception e) { break ; } byte [] sql = pkg.getData(); byte [] result = null ; Exception e = null ; try { result = exe.execute(sql); } catch (Exception e1) { e = e1; e.printStackTrace(); } pkg = new Package (result, e); try { packager.send(pkg); } catch (Exception e1) { e1.printStackTrace(); break ; } } exe.close(); try { packager.close(); } catch (Exception e) { e.printStackTrace(); } } }
Launcher 这个类是服务器的启动入口,这个类解析了命令行参数。很重要的参数就是-open或者-create。Launcher根据这两个参数,来决定是创建数据库文件,还是启动一个已有的数据库;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 public class Launcher { public static final int port = 9999 ; public static final long DEFALUT_MEM = (1 << 20 ) * 64 ; public static final long KB = 1 << 10 ; public static final long MB = 1 << 20 ; public static final long GB = 1 << 30 ; public static void main (String[] args) throws ParseException { Options options = new Options (); options.addOption("open" , true , "-open DBPath" ); options.addOption("create" , true , "-create DBPath" ); options.addOption("mem" , true , "-mem 64MB" ); CommandLineParser parser = new DefaultParser (); CommandLine cmd = parser.parse(options, args); if (cmd.hasOption("open" )) { openDB(cmd.getOptionValue("open" ), parseMem(cmd.getOptionValue("mem" ))); return ; } if (cmd.hasOption("create" )) { createDB(cmd.getOptionValue("create" )); return ; } System.out.println("Usage: launcher (open|create) DBPath" ); } private static void createDB (String path) { TransactionManager tm = TransactionManager.create(path); DataManager dm = DataManager.create(path, DEFALUT_MEM, tm); VersionManager vm = new VersionManagerImpl (tm, dm); TableManager.create(path, vm, dm); tm.close(); dm.close(); } private static void openDB (String path, long mem) { TransactionManager tm = TransactionManager.open(path); DataManager dm = DataManager.open(path, mem, tm); VersionManager vm = new VersionManagerImpl (tm, dm); TableManager tbm = TableManager.open(path, vm, dm); new Server (port, tbm).start(); } private static long parseMem (String memStr) { if (memStr == null || "" .equals(memStr)) { return DEFALUT_MEM; } if (memStr.length() < 2 ) { Panic.panic(Error.InvalidMemException); } String unit = memStr.substring(memStr.length() - 2 ); long memNum = Long.parseLong(memStr.substring(0 , memStr.length() - 2 )); switch (unit) { case "KB" : return memNum * KB; case "MB" : return memNum * MB; case "GB" : return memNum * GB; default : Panic.panic(Error.InvalidMemException); } return DEFALUT_MEM; } }
Client 解析客户输入的内容;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Client { private RoundTripper rt; public Client (Packager packager) { this .rt = new RoundTripper (packager); } public byte [] execute(byte [] stat) throws Exception { Package pkg = new Package (stat, null ); Package resPkg = rt.roundTrip(pkg); if (resPkg.getErr() != null ) { throw resPkg.getErr(); } return resPkg.getData(); } public void close () { try { rt.close(); } catch (Exception e) { } } }
RoundTripper 用于发送请求并接受响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class RoundTripper { private Packager packager; public RoundTripper (Packager packager) { this .packager = packager; } public Package roundTrip (Package pkg) throws Exception { packager.send(pkg); return packager.receive(); } public void close () throws Exception { packager.close(); } }
Shell 用于接受用户的输入,并调用Client.execute()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Shell { private Client client; public Shell (Client client) { this .client = client; } public void run () { Scanner sc = new Scanner (System.in); try { while (true ) { System.out.print(":> " ); String statStr = sc.nextLine(); if ("exit" .equals(statStr) || "quit" .equals(statStr)) { break ; } try { byte [] res = client.execute(statStr.getBytes()); System.out.println(new String (res)); } catch (Exception e) { System.out.println(e.getMessage()); } } } finally { sc.close(); client.close(); } } }
Launcher 启动客户端并连接服务器;
1 2 3 4 5 6 7 8 9 10 11 12 public class Launcher { public static void main (String[] args) throws UnknownHostException, IOException { Socket socket = new Socket ("127.0.0.1" , 9999 ); Encoder e = new Encoder (); Transporter t = new Transporter (socket); Packager packager = new Packager (t, e); Client client = new Client (packager); Shell shell = new Shell (client); shell.run(); } }