小记
3DGS
组会…
1 本周论文核心内容
本周我汇报的论文是EDGS 和 Mobile-GS这两篇论文,
2 现有方法的问题与瓶颈
首先EDGS这篇论文的核心是针对动态场景的3DGS方法进行效率优化。目前动态3DGS的方法,虽然渲染质量不错,但存在一个关键瓶颈,就是会为整个场景生成大量冗余的高斯点,并且每个时间帧都需要通过MLP查询所有高斯点的时变属性,严重拖慢了渲染速度。
EDGS的创新就在于通过一种稀疏的时变属性建模方法,显著减少了需要处理的高斯数量,从而在保证甚至提升渲染质量的同时,实现了渲染速度的飞跃。
如图所示可以看到 随着高斯点数量的增加,渲染帧率急剧下降。这是因为像Deformable 3DGS这类方法,试图用高斯点去拟合每一个训练视图在每一个时间步的状态,导致了大量的冗余。
并且真实场景中往往包含大量的静态区域,这些区域的高斯属性是时不变的,但现有方法却“一视同仁”地在每个时间步用MLP去查询它们的属性,这不仅是计算浪费,还可能导致静态区域在渲染视频中出现不该有的抖动。
第3页:EDGS方法总览
针对上述问题,EDGS提出了一个非常巧妙的解决方案。它的核心思想是将动态场景分解为稀疏的、基于锚点网格的表示。整个流程可以概括为四步:
1)从SfM点云初始化一个稀疏的锚点网格;
2)使用一个轻量级的时间掩码MLP 无监督地判断每个锚点属于静态区域还是动态区域;
3)对于静态区域的锚点,其下属的高斯点只计算时不变属性(如颜色、透明度);
4)对于动态区域的锚点,才使用MLP查询其位置、旋转等时变属性,并且下属高斯点的运动通过一个径向基函数(RBF)核,根据锚点的运动来推算。这样就实现了对时变属性的选择性计算,大大减少了MLP的查询负担。
第4页:创新点一:稀疏锚点网格与属性推导
EDGS采用的稀疏锚点网格作为基础表示。它并不直接存储海量的高斯点,而是从一个稀疏的锚点网格出发,每个锚点附带一组特征。高斯点的属性MLP从这个锚点特征解码出来的。
对于时变属性,被分解为一个基础值和一个随时间变化的偏移量,这个偏移量由MLP根据时间编码和锚点特征计算。
第5页:创新点二:基于RBF核的语义运动建模
第二个EDGS建模运动的方式。以往方法要么假设物体是刚性的,要么使用KNN来关联控制点和高斯点。EDGS提出了一个更优雅的方案:使用径向基函数(RBF)核。首先通过一个变形MLP计算出锚点自身的运动偏移,然后,每个下属高斯点的运动偏移量,是通过计算其特征与锚点特征的RBF相似度来加权的。相当于语义上越接近锚点的高斯点,其运动与锚点越一致;语义上差异较大的点(比如物体的边缘或可变形部分),则可以有自己独特的运动。这是一种语义层面的运动建模,比单纯的几何距离(KNN)更合理,尤其适合处理非刚性变形和物体分离的情况。
第6页:创新点三:无监督静态区域过滤
对静态区域的过滤,这个方法引入了一个二分类MLP,直接根据锚点的特征来预测该锚点是否属于动态区域。这个MLP的训练完全是无监督的,仅通过一个正则化损失项来鼓励尽可能少的锚点被标记为动态。如图所示,红色锚点覆盖了动态物体,而绿色锚点则分布在静态背景上。
使得在渲染时,可以跳过对大量静态锚点的属性查询,这是速度提升的关键。
第7页:实验结果(NeRF-DS数据集)
我们来看实验结果。在NeRF-DS数据集上,如表所示,EDGS在绝大多数场景和指标上都达到了最优或次优的水平,尤其是在平均PSNR和SSIM上取得了最好的成绩。这证明了其方法在提升速度的同时,并没有牺牲渲染质量,反而因为优化过程更集中(只优化动态区域锚点),质量有所提升。
第8页:实验结果(HyperNeRF数据集)
在更具挑战性的HyperNeRF数据集上,EDGS的优势更加明显。如表2所示,它的PSNR和MS-SSIM都是最高的。最关键的是,其渲染速度达到了惊人的117 FPS,远超其他方法(第二名4DGS为34 FPS)。同时,其训练时间仅需20分钟,并且只有7K个高斯点需要查询时变属性,这些都充分体现了其高效性。
第9页:消融实验与效果对比
论文还进行了充分的消融实验。表3表明,锚点网格策略是渲染速度的基石,而时间掩码MLP则在速度和质量上都有进一步的提升。表4则对比了不同的运动建模策略,验证了RBF核的有效性,其性能优于刚性变换和KNN等方法。从视觉效果看,图3、4、5都显示EDGS能够重建更精细的细节,并且有效解决了静态区域的抖动问题。
最后我来总结一下。EDGS这篇工作的核心贡献在于,它通过稀疏锚点表示、基于RBF的语义运动流和无监督静态区域过滤这三个紧密关联的创新点,精准地命中了动态3DGS渲染的瓶颈——冗余的高斯点数量。它的优势非常突出:渲染速度极快(117 FPS),质量更高,且存储紧凑。
10 mgs
第二篇论文是Mobile-GS,目标是解决3DGS在移动设备上部署的瓶颈。3DGS虽然能实现高质量的新视角合成,但其巨大的计算开销和存储成本严重阻碍了在手机等边缘设备上的实时渲染。如图所示,本文在移动端实现了116 FPS的高分辨率实时渲染,保持视觉质量的同时,将模型存储压缩至4.8MB。”
11 性能瓶颈分析
“要实现移动端实时渲染,必须解决核心瓶颈。如图所示,在原始3DGS的渲染管线中,基于深度的高斯排序(Depth Sorting) 是最大的性能开销。这是因为传统的Alpha混合要求高斯必须按从近到远的顺序渲染。右图证明,一旦移除排序,帧率可获得数倍提升。因此,本文的第一个关键创新点就是彻底摒弃排序操作。”
12 核心方法概览
图片清晰地对比了文章的Mobile-GS与原始3DGS的渲染管线。文章摒弃了传统的分块渲染和排序流程,转而采用一种深度感知的无序渲染(Depth-aware Order-independent Rendering) 方案。该方案允许所有相关高斯并行地贡献到像素颜色,并通过一个加权的累加公式来模拟近处高斯贡献更大的物理直觉,从而在单次渲染中完成合成。”
13 深度感知无序渲染
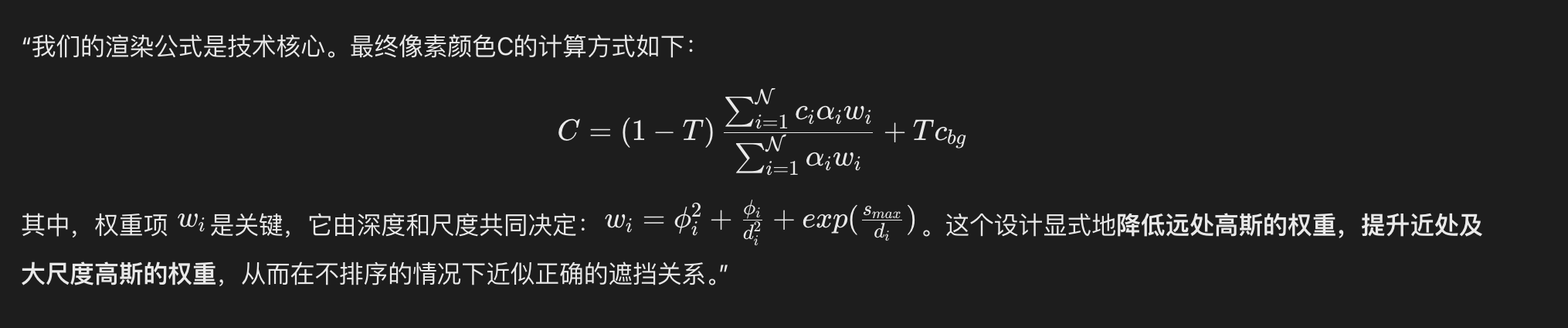
14 神经视角依赖增强
然而,无序渲染会引入透明伪影,尤其是在重叠区域。为此,我们提出了神经视角依赖增强策略,如图所示。我们设计了一个轻量级MLP,输入包括高斯的尺度、旋转、球谐系数以及相机-高斯方向向量,输出一个视角依赖的不透明度修正量。这个网络能动态地抑制被遮挡区域的透明度,显著提升渲染质量。”
15 压缩与蒸馏技术
在压缩方面,有两个主要贡献。首先是一阶球谐蒸馏。原始3DGS使用三阶SH(48个系数)表示外观,参数量大。我们在一个预训练的教师模型指导下,将知识蒸馏到仅使用一阶SH(12个系数)的学生模型中,大幅降低了存储和计算开销。第二是神经向量量化(Neural Vector Quantization, NVQ),我们将高斯参数分组,用K-means聚类和多个小型码本进行量化,并进一步用霍夫曼编码压缩,极致减少存储。”
16 基于贡献的剪枝
“为了减少高斯数量,我们提出了基于贡献的剪枝(Contribution-based Pruning) 策略。其核心洞察是:低不透明度(Low Opacity)和小尺度(Small Scale)的高斯对最终图像的贡献是微不足道的。我们在训练过程中,持续统计每个高斯的不透明度和最大尺度,并基于分位数阈值累积‘投票’。只有那些持续被判定为低贡献的高斯才会被最终剪枝,这在大量减少高斯数量的同时,最大程度地保留了视觉质量。”
17 主要实验结果(定量)
“在定量实验上,如Table 1和2所示,我们的方法在Mip-NeRF 360等标准数据集上,其PSNR指标与原始3DGS相当,甚至略有超越。最关键的是,在移动端(Snapdragon 8 Gen 3)上,我们的方法达到了127 FPS的渲染速度,远超其他轻量级方法(如SortFreeGS的24 FPS)。同时,模型存储占用仅4.6 MB,峰值内存也最低,充分证明了其移动端部署的优越性。”
18 主要实验结果(定性)与消融实验
在定性结果上,如Figure 5所示,我们的方法渲染出的图像清晰、一致,在视角依赖效果上甚至优于原始3DGS。消融实验(Table 3和Figure 7)则系统地验证了每个组件的必要性。例如,移除神经视角依赖增强后,PSNR大幅下降,透明伪影明显;而移除神经量化则导致存储暴涨至121 MB。这些实验共同表明,我们的每个设计都是实现高质量、高效率移动端渲染所不可或缺的。”
19 总结
Mobile-GS是首个专为移动设备设计的实时高斯泼溅方案。其核心创新在于:1)深度感知的无序渲染,根除了排序瓶颈;2)神经视角依赖增强,补偿了无序渲染的质量损失;3)一阶SH蒸馏与神经向量量化,实现了极致的模型压缩。实验证明,该方法在移动端实现了实时渲染速度(127 FPS)、极小的存储占用(<5MB) 和媲美原版的视觉质量,为移动AR/VR等应用提供了强大的技术基础。”